Show the code
library(dplyr)
library(readr)
library(knitr)
library(ggplot2)
library(leaflet)
library(readxl)
library(gridExtra)
deprem_analiz <- read.csv("Deprem_senaryosu_analiz_sonuçlar.csv")
deprem_analiz$ilce_adi <- gsub("Ý", "İ", deprem_analiz$ilce_adi, fixed = TRUE)
deprem_analiz$ilce_adi <- gsub("Ð", "Ğ", deprem_analiz$ilce_adi, fixed = TRUE)
deprem_analiz$ilce_adi <- gsub("Þ", "Ş", deprem_analiz$ilce_adi, fixed = TRUE)
deprem_analiz$ilce_adi <- gsub("Þ", "Ş", deprem_analiz$ilce_adi, fixed = TRUE)
deprem_analiz <- data.frame(lapply(deprem_analiz, function(v) {
if (is.character(v)) return(tolower(v))
else return(v)
}))
nufus <- read_excel("belediye_nufuslar_2019.xlsx")
nufus <- data.frame(lapply(nufus, function(v) {
if (is.character(v)) return(tolower(v))
else return(v)
}))
nufus$Belediyeler <- gsub("belediyesi", "", nufus$Belediyeler)
istanbul_coordinates <- read.csv("istanbul_koordinatlar.csv")
istanbul_coordinates <- data.frame(lapply(istanbul_coordinates, function(v) {
if (is.character(v)) return(tolower(v))
else return(v)
}))
istanbul_df <- data.frame(read_excel("istanbul_df.xlsx"))
istanbul_df <- cbind(istanbul_df, nufus)
istanbul_df <- istanbul_df %>%
select(-Belediyeler) %>%
select(ilce_adi, X2019.yılı.nüfusları, cok_agir_hasarli_bina_sayisi:last_col())
colnames(deprem_analiz)[1:4] <- c("id", "ilce_adi", "mahalle_adi", "mahalle_kodu")
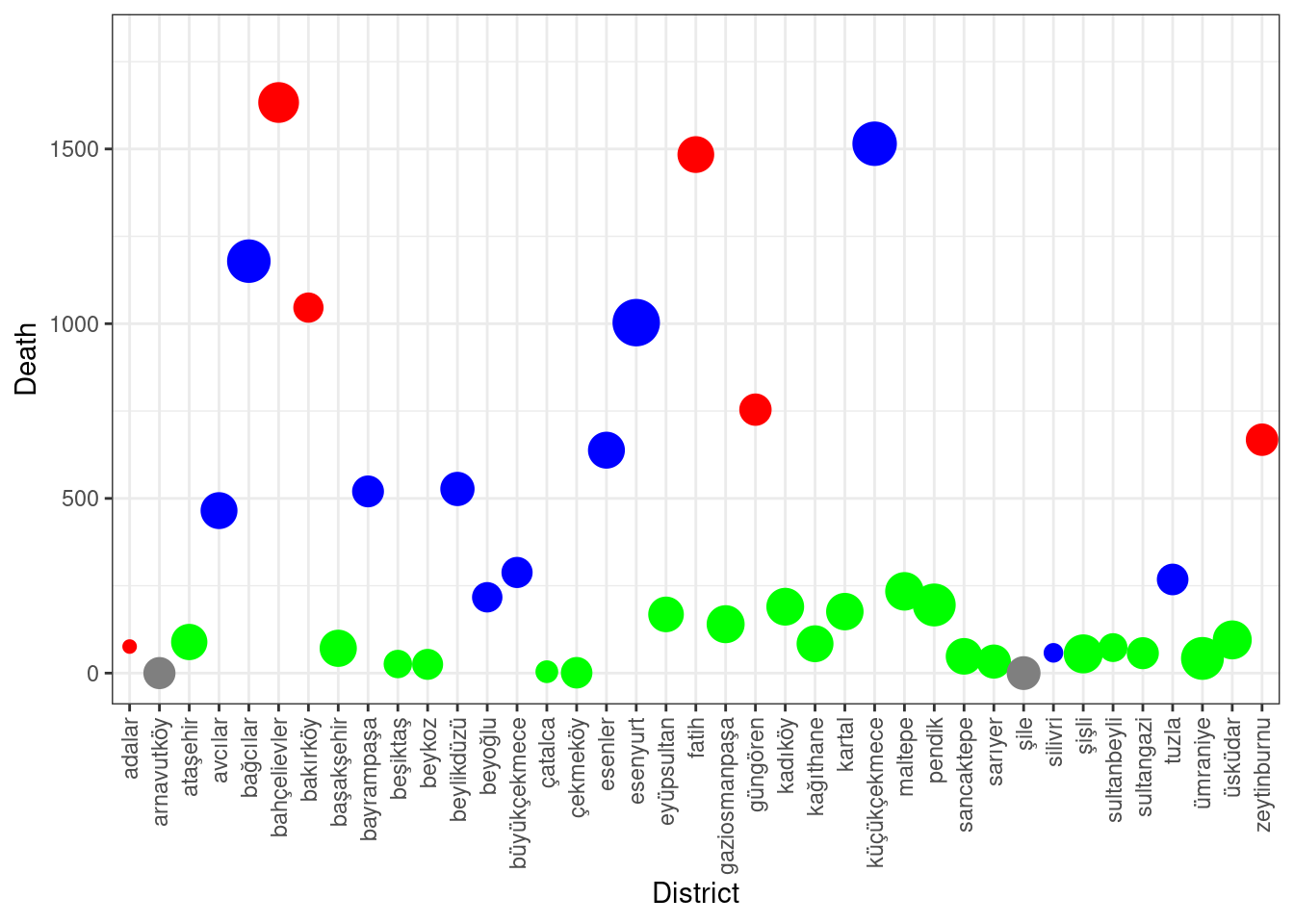
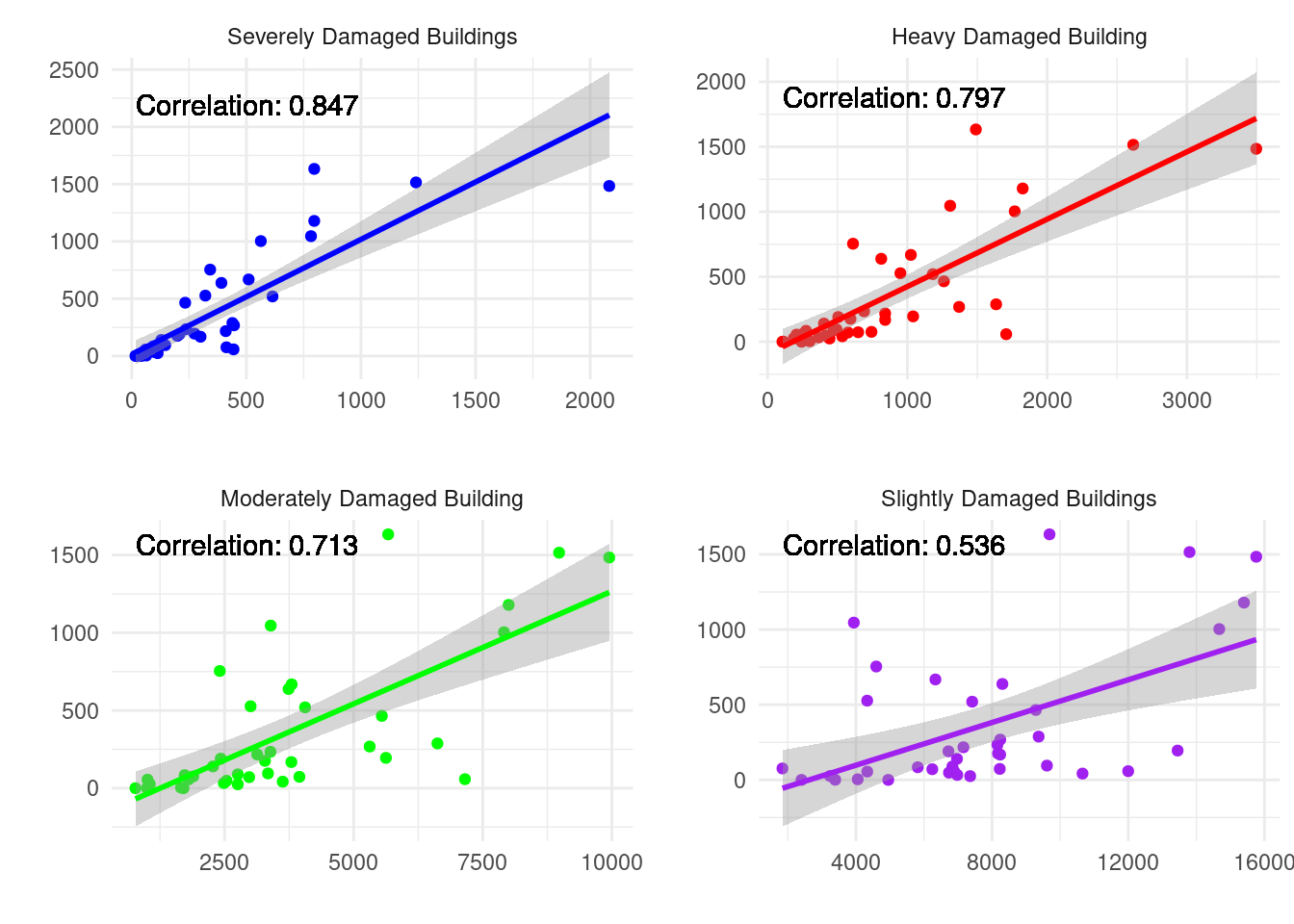
district_sum <- deprem_analiz %>% group_by(ilce_adi) %>% summarise(
total_cok_agir_hasarli = sum(cok_agir_hasarli_bina_sayisi),
total_agir_hasarli = sum(agir_hasarli_bina_sayisi),
total_orta_hasarli = sum(orta_hasarli_bina_sayisi),
total_hafif_hasarli = sum(hafif_hasarli_bina_sayisi),
total_can_kaybi = sum(can_kaybi_sayisi),
total_agir_yarali = sum(agir_yarali_sayisi),
total_hafif_yarali = sum(hafif_yarali_sayisi),
.groups = 'drop')
district_sum <- data.frame(district_sum)
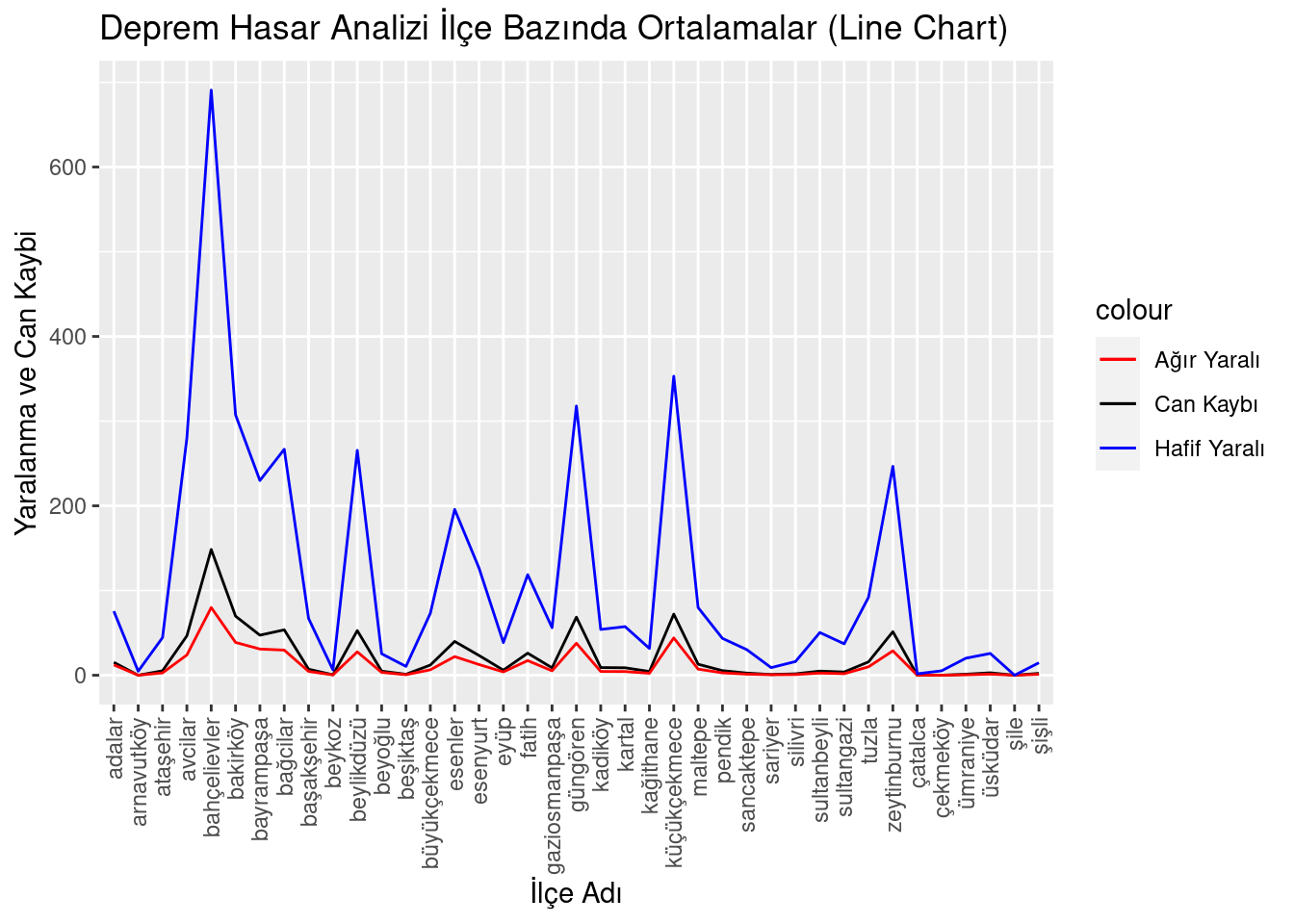
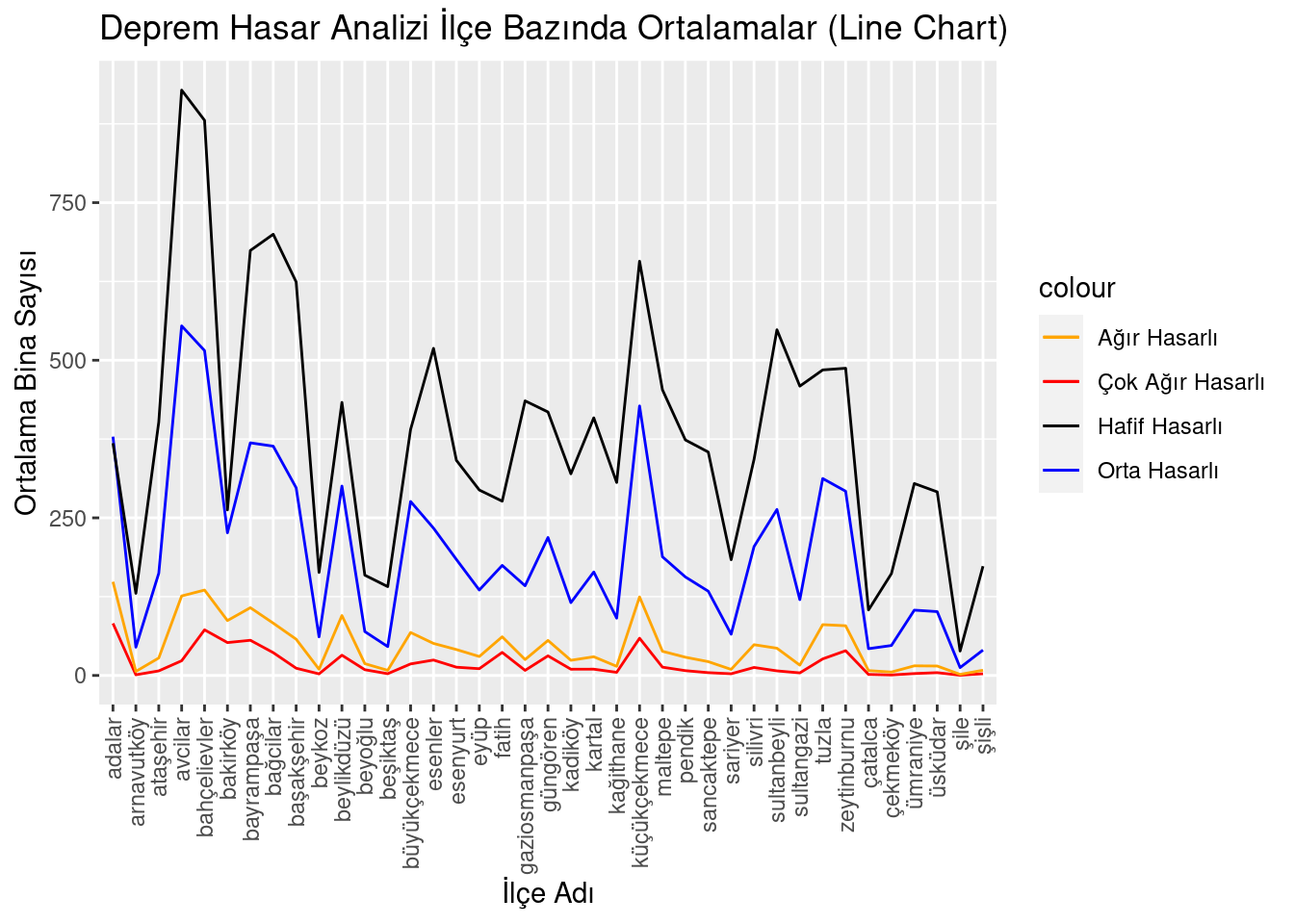
district_avg <- deprem_analiz %>% group_by(ilce_adi) %>% summarise(
avg_cok_agir_hasarli = mean(cok_agir_hasarli_bina_sayisi),
avg_agir_hasarli = mean(agir_hasarli_bina_sayisi),
avg_orta_hasarli = mean(orta_hasarli_bina_sayisi),
avg_hafif_hasarli = mean(hafif_hasarli_bina_sayisi),
avg_can_kaybi = mean(can_kaybi_sayisi),
avg_agir_yarali = mean(agir_yarali_sayisi),
avg_hafif_yarali = mean(hafif_yarali_sayisi),
.groups = 'drop')
district_avg$ilce_adi <- factor(district_avg$ilce_adi, levels = unique(district_avg$ilce_adi))
kable(head(district_avg, 10), caption="Data")| ilce_adi | avg_cok_agir_hasarli | avg_agir_hasarli | avg_orta_hasarli | avg_hafif_hasarli | avg_can_kaybi | avg_agir_yarali | avg_hafif_yarali |
|---|---|---|---|---|---|---|---|
| adalar | 82.600000 | 148.600000 | 378.80000 | 368.4000 | 15.2000000 | 12.2000000 | 75.600000 |
| arnavutköy | 1.078947 | 6.394737 | 44.84211 | 130.2632 | 0.0000000 | 0.0000000 | 4.710526 |
| ataşehir | 7.235294 | 27.705882 | 162.11765 | 401.9412 | 5.2352941 | 2.7647059 | 44.411765 |
| avcilar | 23.300000 | 126.100000 | 554.50000 | 928.5000 | 46.5000000 | 23.9000000 | 279.900000 |
| bahçelievler | 72.363636 | 135.454545 | 515.27273 | 880.5455 | 148.4545455 | 79.9090909 | 690.818182 |
| bakirköy | 52.133333 | 87.066667 | 226.26667 | 262.6000 | 69.7333333 | 38.7333333 | 307.333333 |
| bayrampaşa | 55.818182 | 107.454545 | 369.00000 | 674.0909 | 47.2727273 | 30.9090909 | 229.909091 |
| bağcilar | 36.181818 | 82.954545 | 363.68182 | 699.8636 | 53.5909091 | 29.6363636 | 266.772727 |
| başakşehir | 11.500000 | 57.500000 | 297.70000 | 624.3000 | 7.1000000 | 4.5000000 | 67.000000 |
| beykoz | 2.511111 | 9.844444 | 61.24444 | 163.4667 | 0.5555556 | 0.3555556 | 6.311111 |