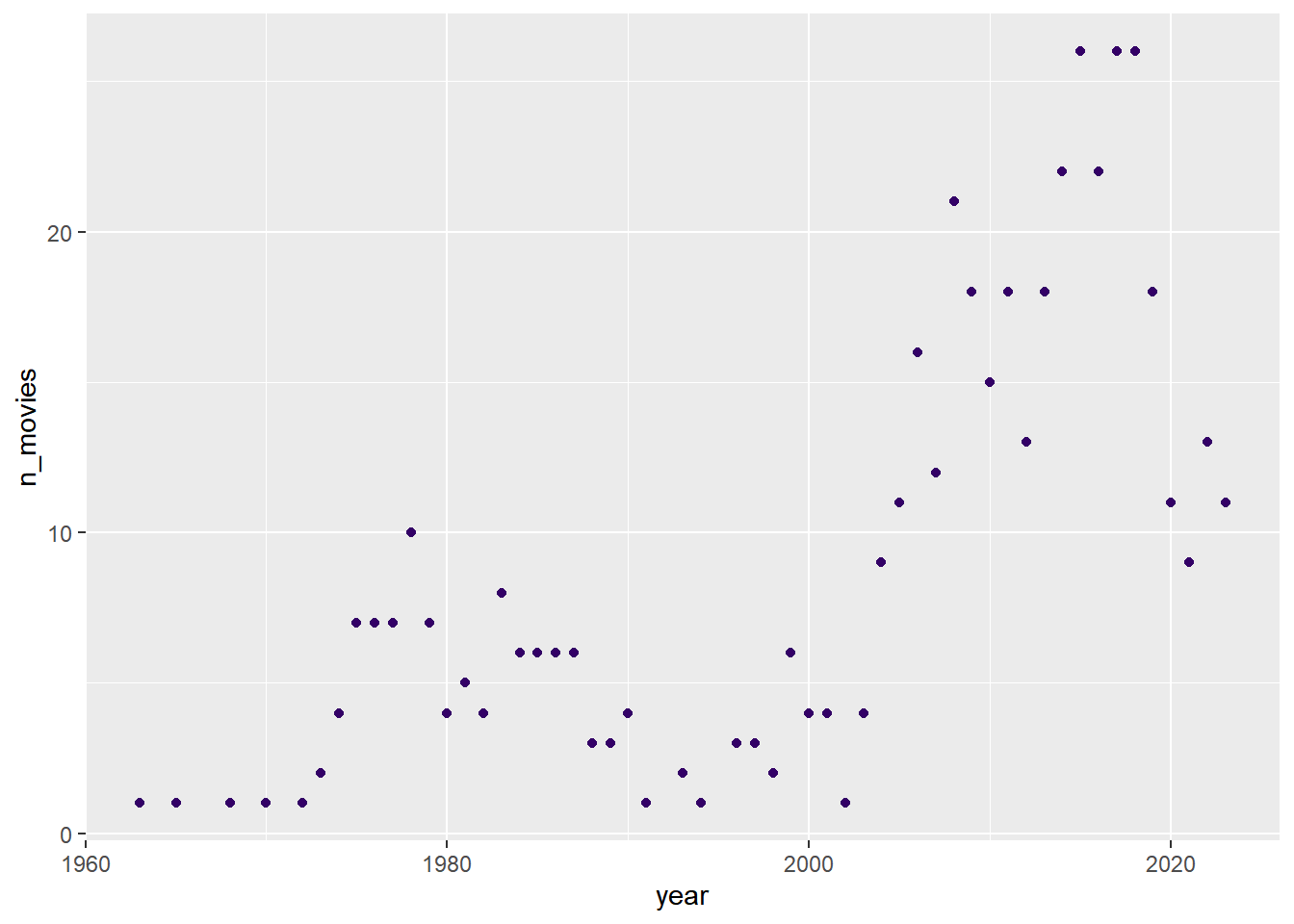
For the first part of the assignment I was required to scrap Turkish movie data from the IMDB site using the advanced movie search. You can see the code I used to scrap the html and tidy it into a data frame called movie_info.
title year rate
1 Hababam Sinifi 1975 9.2
2 CM101MMXI Fundamentals 2013 9.1
3 Tosun Pasa 1976 8.9
4 Hababam Sinifi Sinifta Kaldi 1975 8.9
5 Süt Kardesler 1976 8.8
The 5 Worst Rated movies:
title year rate
466 Cumali Ceber 2 2018 1.2
467 Müjde 2022 1.2
468 15/07 Safak Vakti 2021 1.2
469 Cumali Ceber: Allah Seni Alsin 2017 1.0
470 Reis 2017 1.0
Out of the top rated movies, I have watched all except for Tosun Pasa. Since the IMDb ratings are based on subjective rates of people, although I think there are movies which deserve top 5 more, I can not say that these movies do not deserve their ratings. The bottom rated movies however, are disliked by the majority of the users so there must be something wrong with them to receive these ratings.
b)
My Favorites
title year rate votes duration
39 G.O.R.A. 2004 8 66033 2h 7m
title year rate votes duration
90 Mucize 2015 7.6 13899 2h 16m
I adore G.O.R.A. and Mucize. I think both got the ratings they deserved, but Mucize has a special place in my heart with its beautiful sceneries, convincing acting and accents, good ending, and emotional story.
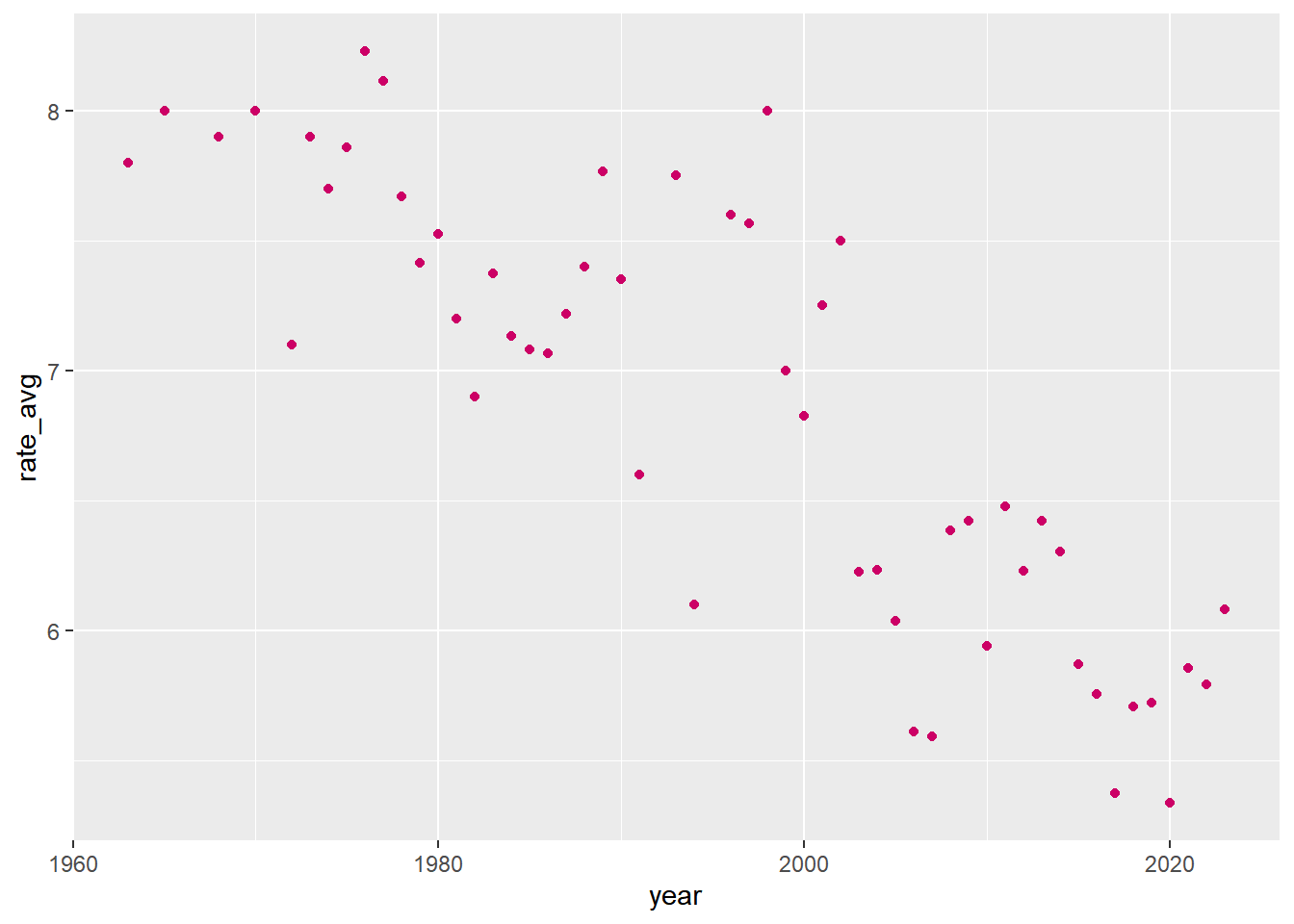
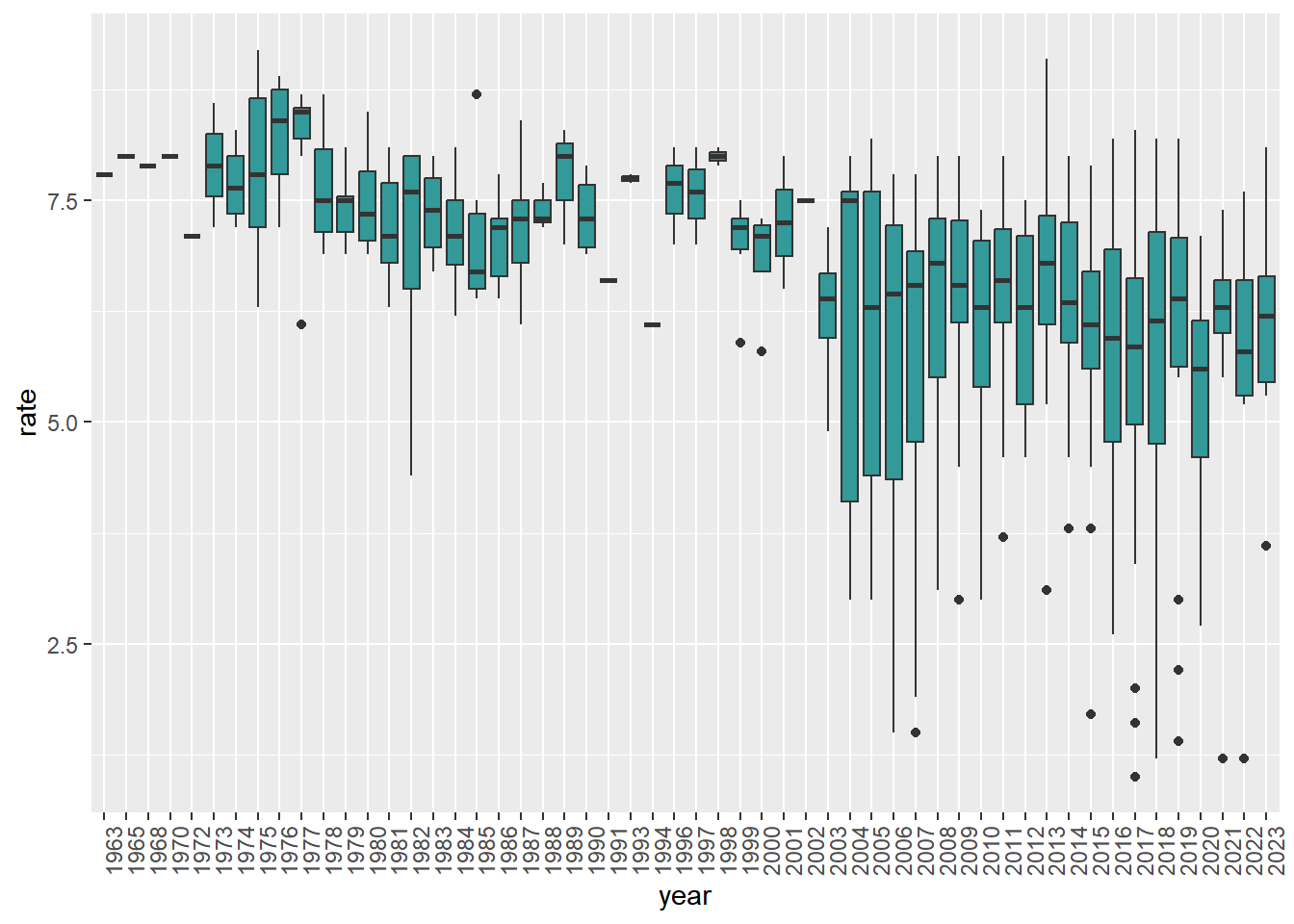
The box plot shows that other than a few exceptions means and lower quantiles for movie ratings tend to drop over the years. And the lowest rated movies also appear in more recent years.
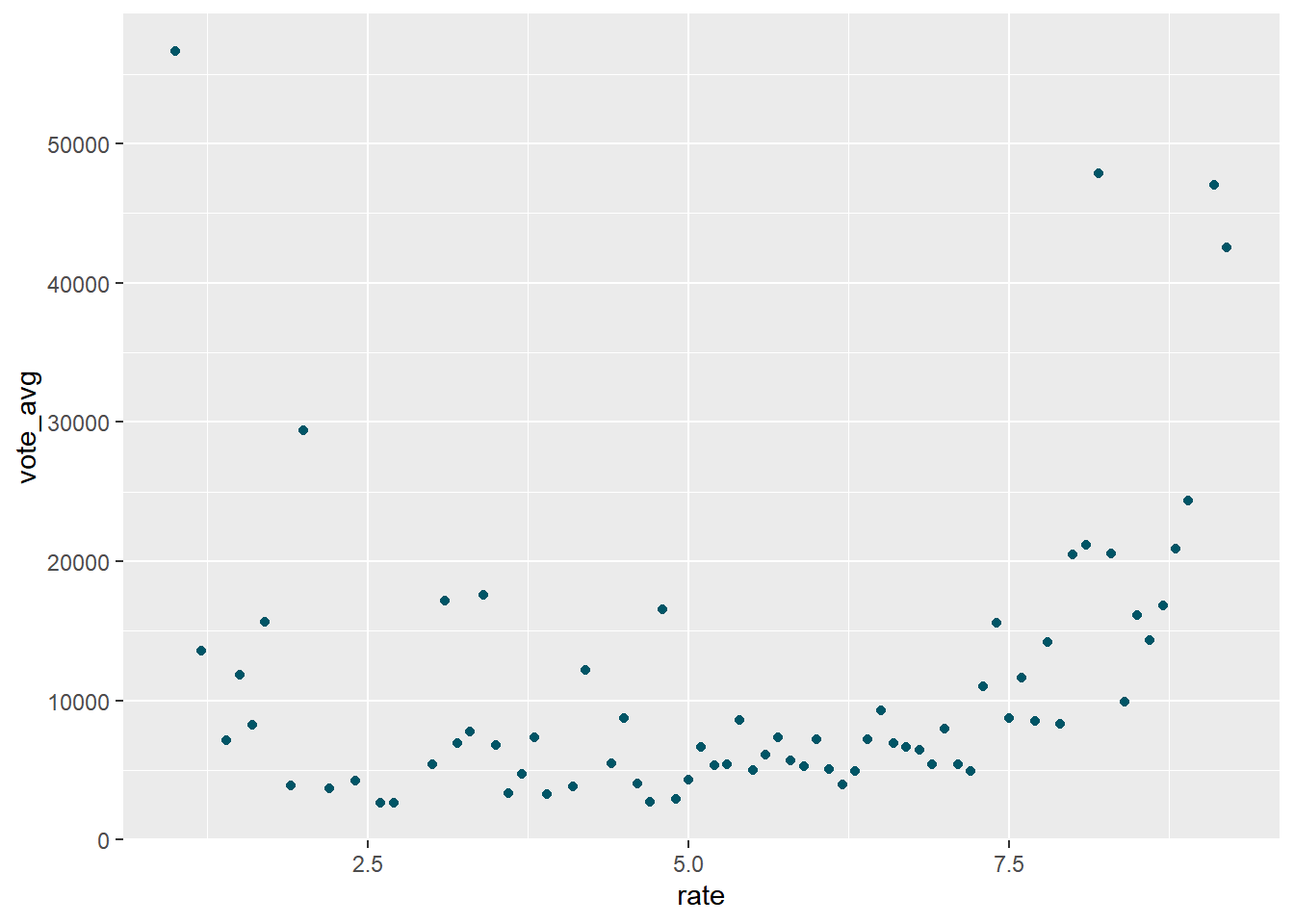
The only conclusion we can come to from this plot is that movies with really high ratings tend to have higher votes, which can be caused by more people watching them because they are good already? Seems pretty natural.