Arrange your data frame in descending order by Rating. Present the top 5 and bottom 5 movies based on user ratings. Have you watched any of these movies? Do you agree or disagree with their current IMDb Ratings?
kable(head(movies_df, 5), caption ="Top 5 Movies Based On User Ratings.")
Top 5 Movies Based On User Ratings.
movie_titles
movie_years
movie_durations
movie_ratings
movie_votes
257
Hababam Sinifi
1975
87
9.2
42509
39
CM101MMXI Fundamentals
2013
139
9.1
46994
273
Tosun Pasa
1976
90
8.9
24325
337
Hababam Sinifi Sinifta Kaldi
1975
95
8.9
24367
321
Süt Kardesler
1976
80
8.8
20883
I disagree with the top parts of this list created based on the scores given by the users. In my opinion, films are created by transferring comments made on certain events, problems or situations to cinema. Therefore, I think that “Yeşil Çam” films are overrated too much, the emotions that are intended to be told in the films made by “Yeşil Çam” are unnecessary. There are much better directors today and much better films are being made, but they cannot get such high scores.
Bottom 5 movies based on user ratings.
Show the code
kable(tail(movies_df, 5), caption ="Bottom 5 Movies Based On User Ratings.")
Bottom 5 Movies Based On User Ratings.
movie_titles
movie_years
movie_durations
movie_ratings
movie_votes
189
Cumali Ceber 2
2018
100
1.2
10227
199
Müjde
2022
48
1.2
9920
245
15/07 Safak Vakti
2021
95
1.2
20606
101
Cumali Ceber: Allah Seni Alsin
2017
100
1.0
39264
150
Reis
2017
108
1.0
73972
Definitely I agree with the bottom part of this list but I can’t explain why. :) :D
Check the ratings of 2-3 of your favorite movies. What are their standings?
Note: This list is not ordered. Please don’t judge me based on this order. Note2: Yes! Recep İvedik 2 is still on the list of funniest movies for me, additionally you can also find the Onur Ünlü’s comments about Recep İvedik movies. Interview here.
Let’s check the ratings of “Babam ve Oğlum”, “Sen Aydınlatırsın Geceyi” and “İşe Yarar Bir Şey”.
Babam ve Oğlum
Show the code
kable(movies_df[movies_df$movie_titles =="Babam ve Oglum",], caption ="Babam ve Oğlum")
Babam ve Oğlum
movie_titles
movie_years
movie_durations
movie_ratings
movie_votes
250
Babam ve Oglum
2005
108
8.2
91016
Show the code
sprintf("Rank of the *Babam ve Oğlum* is %d", which(movies_df$movie_titles=="Babam ve Oglum"))
[1] “Rank of the Babam ve Oğlum is 27”
İşe Yarar Bir Şey
Show the code
kable(movies_df[movies_df$movie_titles =="Ise Yarar Bir Sey",], caption ="İşe Yarar Bir Şey")
İşe Yarar Bir Şey
movie_titles
movie_years
movie_durations
movie_ratings
movie_votes
94
Ise Yarar Bir Sey
2017
104
7.6
5507
Show the code
sprintf("Rank of the *İşe Yarar Bir Şey* is %d", which(movies_df$movie_titles=="Ise Yarar Bir Sey"))
sprintf("Rank of the *Sen Aydınlatırsın Geceyi* is %d", which(movies_df$movie_titles=="Sen Aydinlatirsin Geceyi"))
[1] “Rank of the Sen Aydınlatırsın Geceyi is 68”
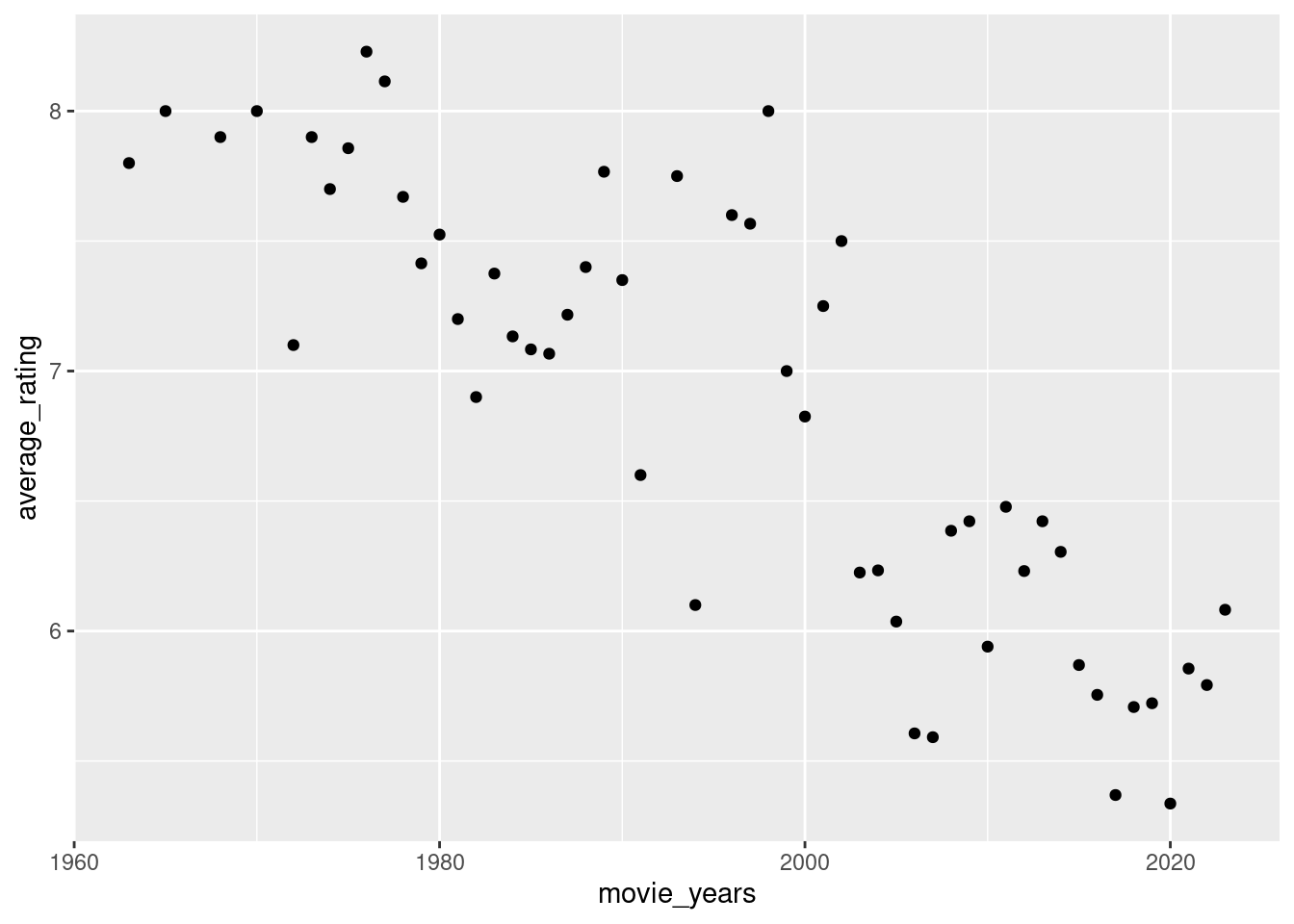
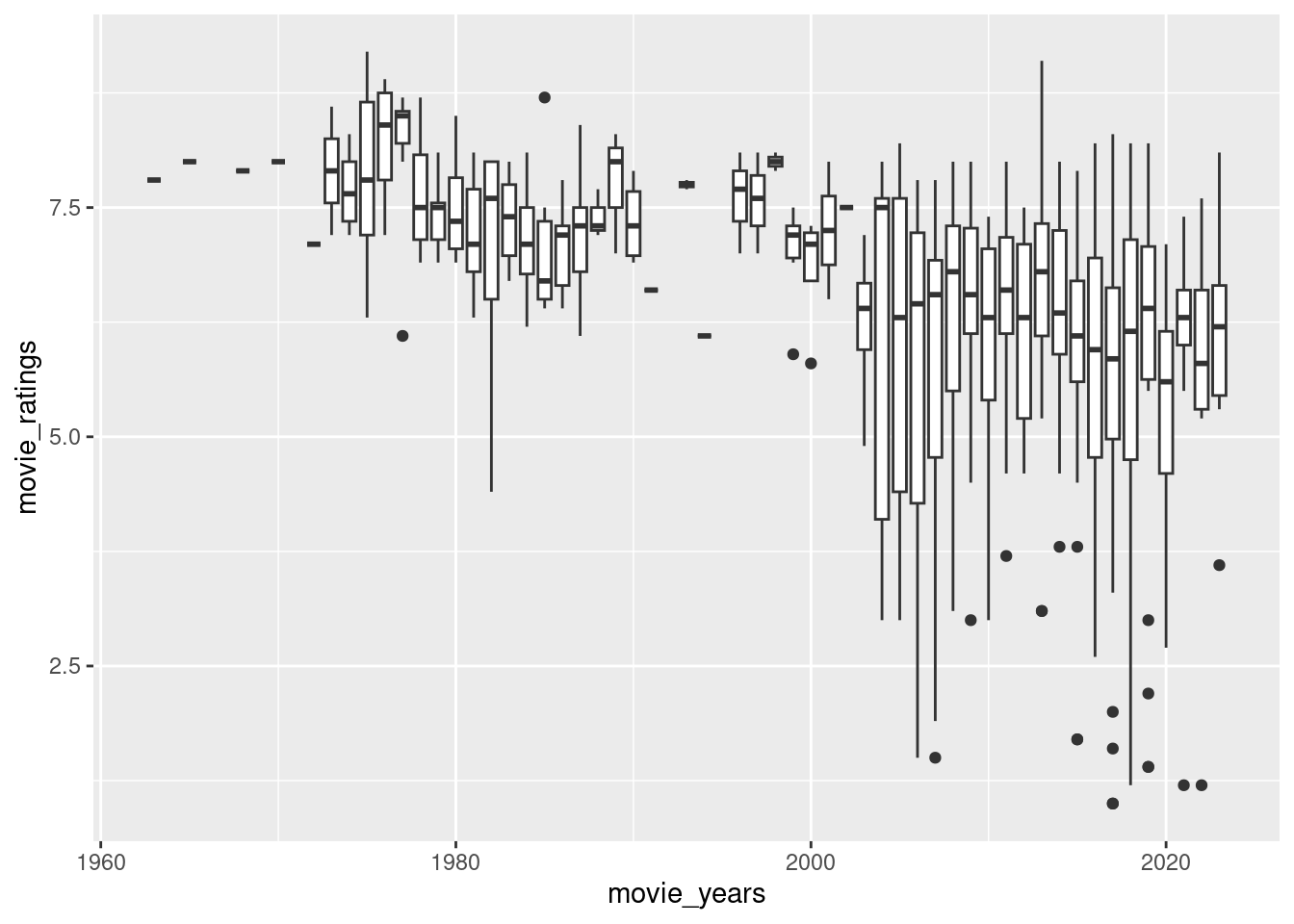
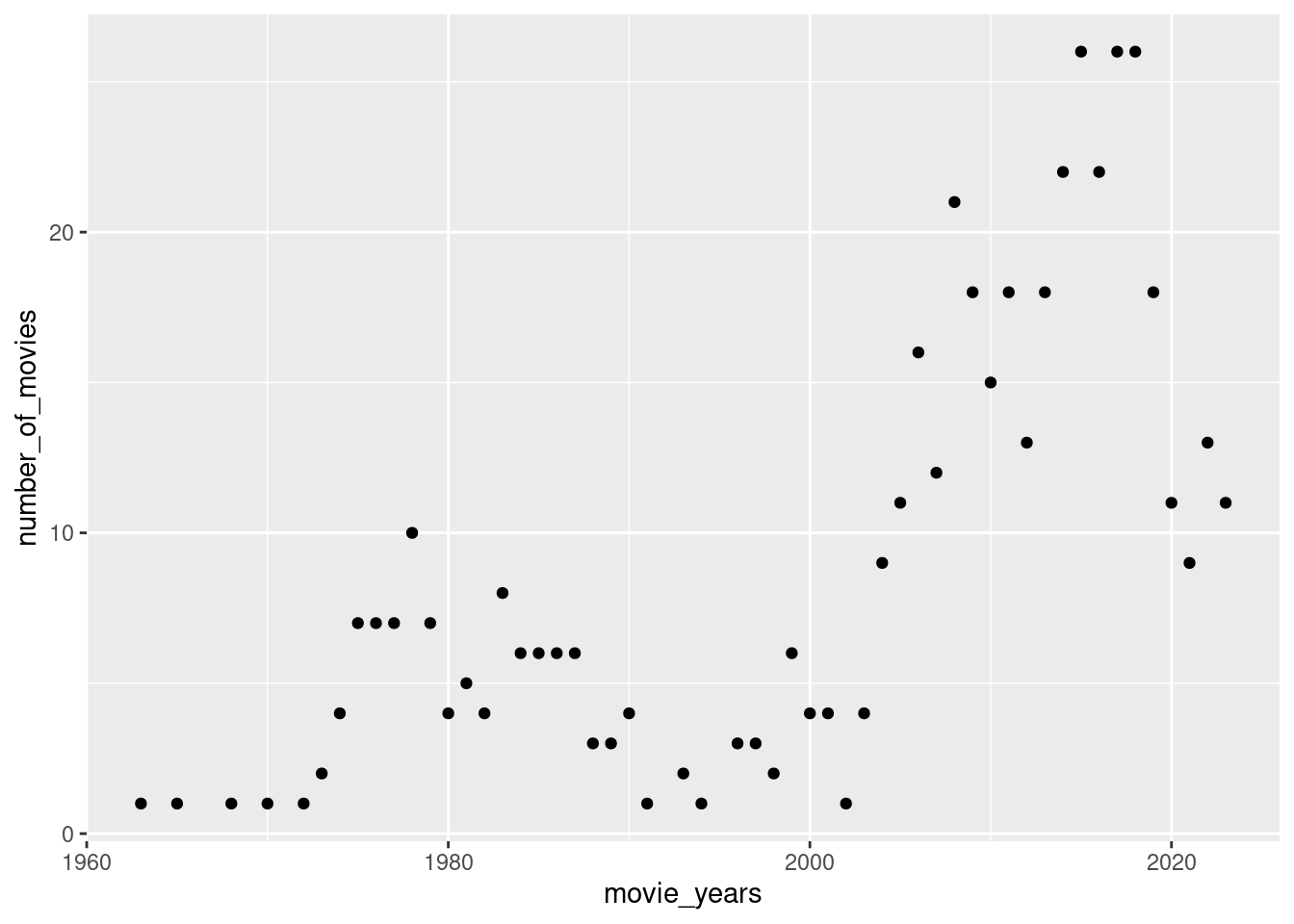
Considering that audience rating is a crucial indicator of movie quality, what canyou infer about the average ratings of Turkish movies over the years? Calculate yearlyrating averages and plot them as a scatter plot. Similarly, plot the number ofmovies over the years. You might observe that using yearly averages could be misleadingdue to the increasing number of movies each year. As an alternative solution,plot box plots of ratings over the years (each year having a box plot showing statisticsabout the ratings of movies in that year). What insights do you gather from the box plot?
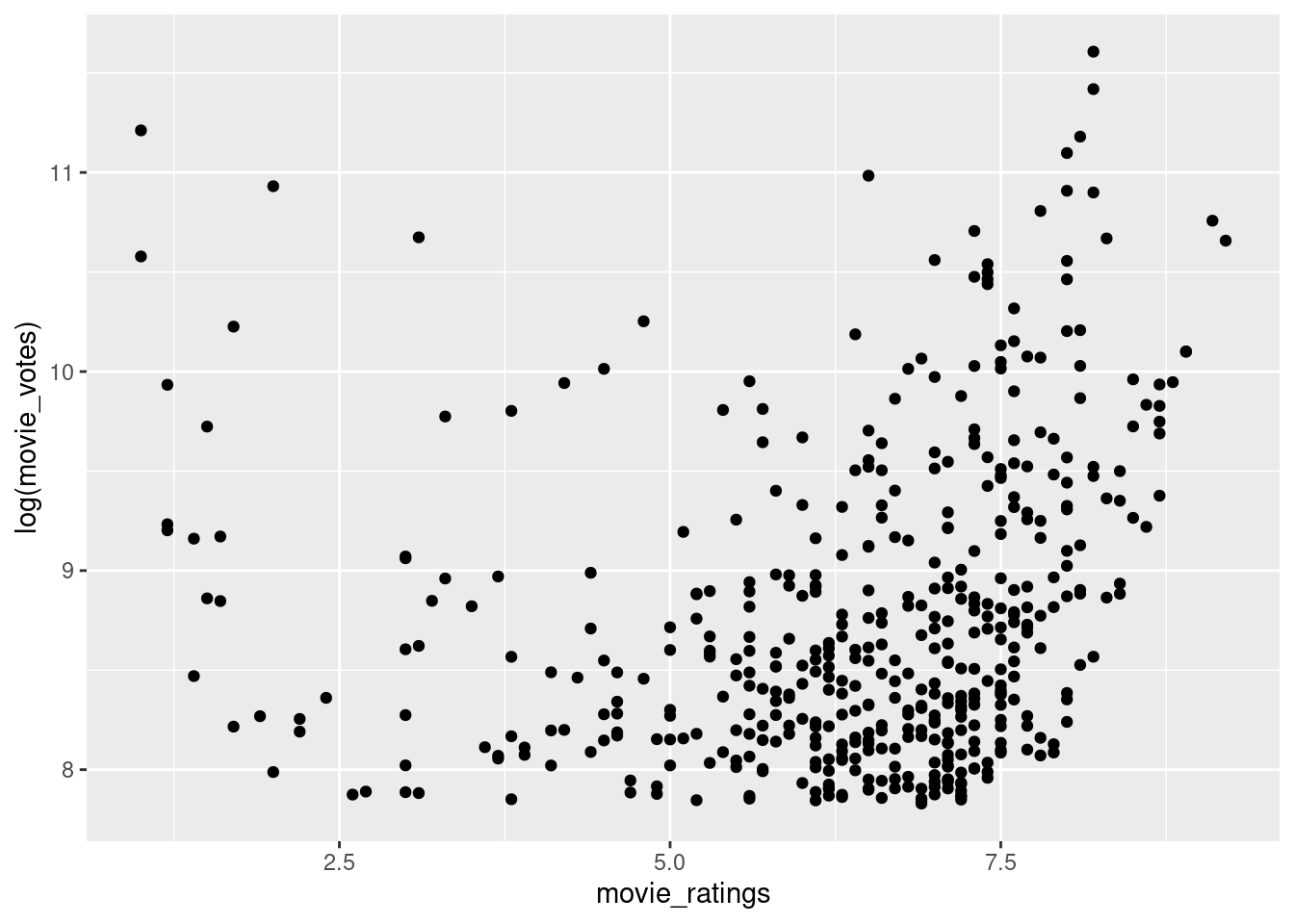
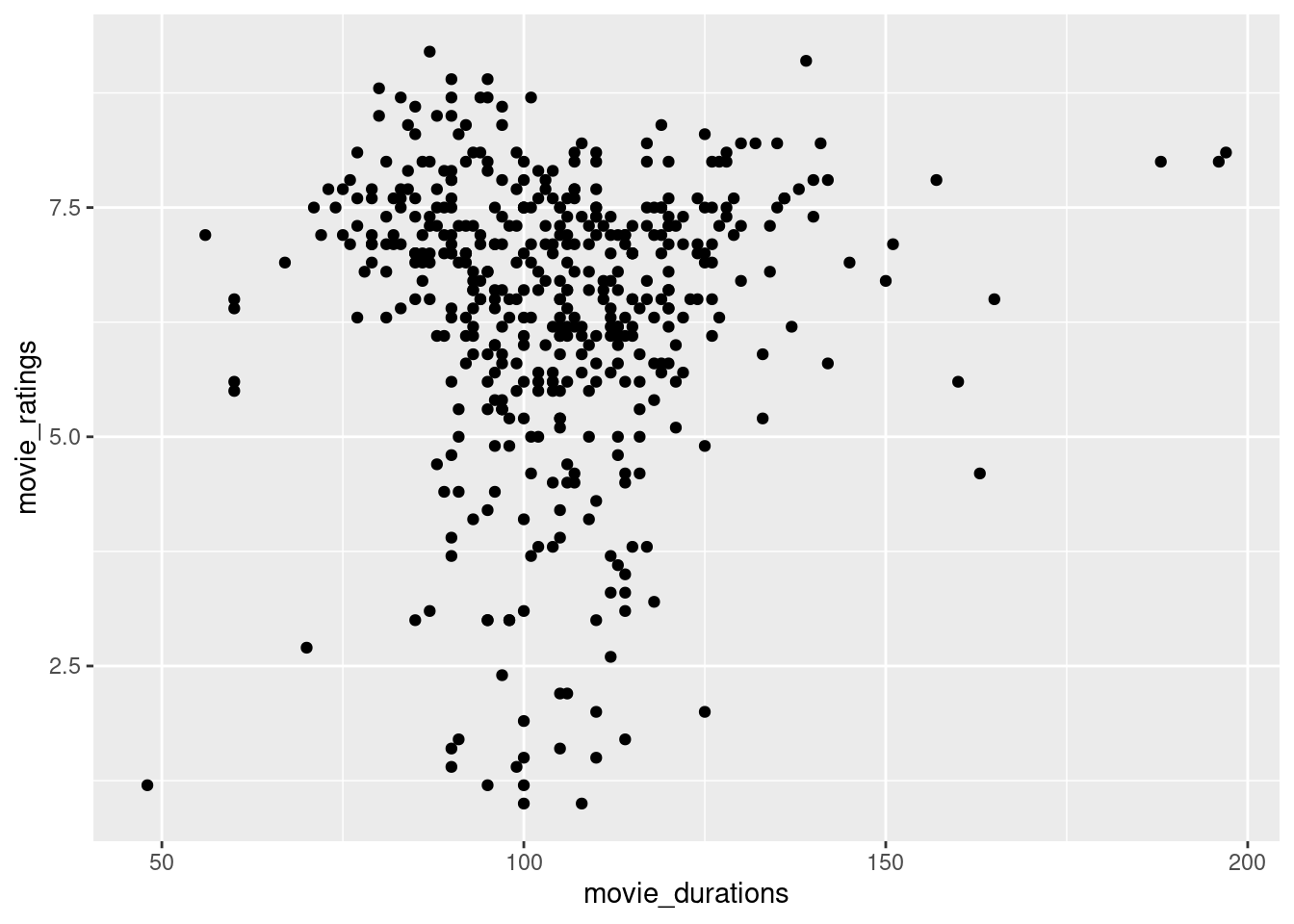
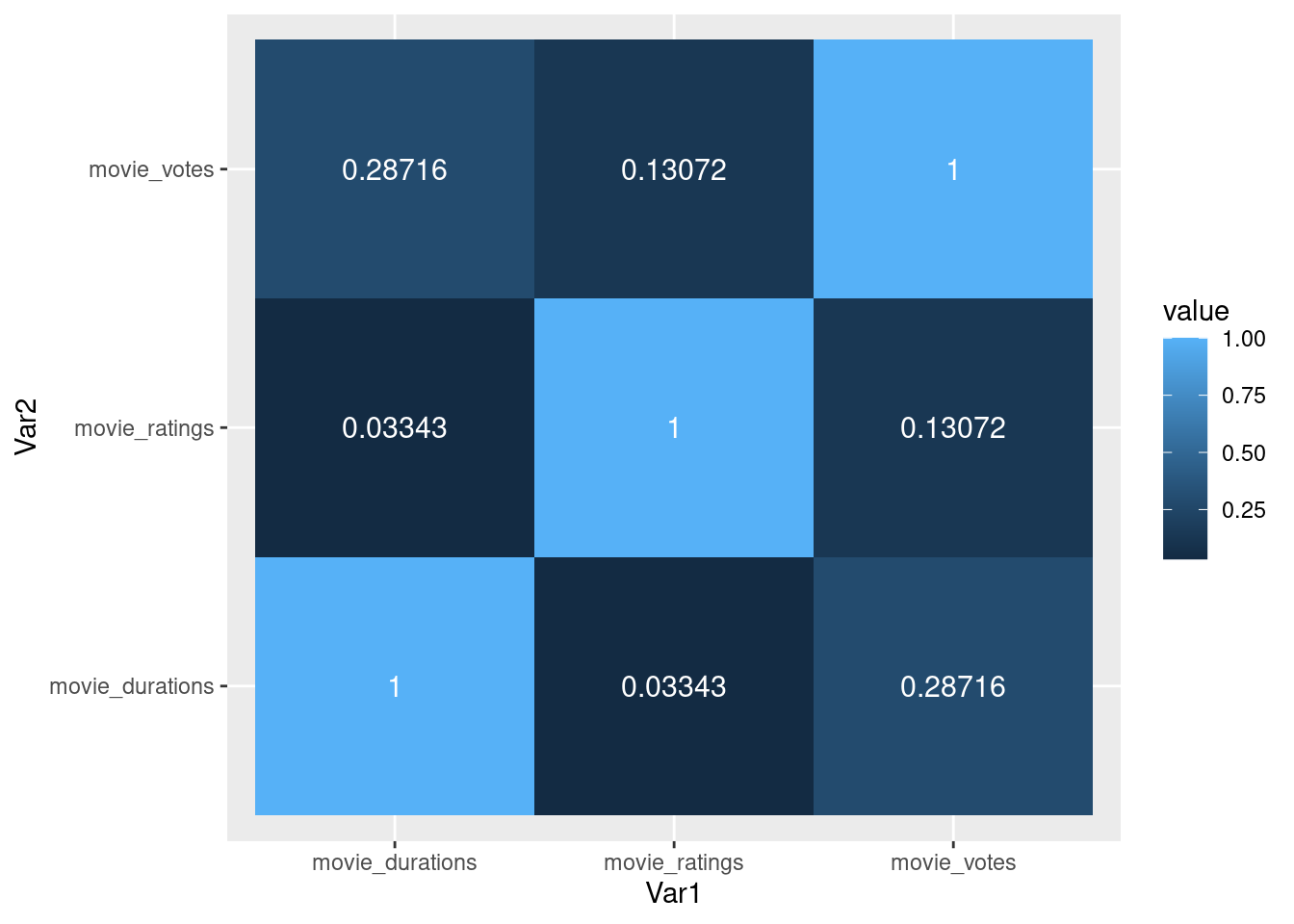
Do you believe there is a relationship between the number of votes a movie received and its rating?Investigate the correlation between Votes and Ratings.
Use IMDb’s Advanced Title Search interface with The Title Type set to “Movie” only,the Country set to “Turkey” with the option “Search country of origin only” active,and the Awards & Recognation set to “IMDB Top 1000”. You should find a total of11 movies.
Show the code
URL_3 ="https://www.imdb.com/search/title/?title_type=feature&groups=top_1000&country_of_origin=TR&count=250"movie_name <-c()movie_year <-c()HTML =read_html(URL_3)title_names <- HTML %>%html_nodes('.ipc-title__text')title_names <-html_text(title_names)title_names <-tail(head(title_names,-1),-1)title_names <-str_split(title_names, " ", n=2)title_names <-unlist(lapply(title_names, function(x) {x[2]}))year <- HTML %>%html_nodes(".sc-43986a27-7.dBkaPT.dli-title-metadata")year <-html_text(year)year <-substr(year, 1, 4)year <-as.numeric(year)movie_name <-append(movie_name, title_names)movie_year <-append(movie_year, year)top1000_df <-data.frame(movie_name, movie_year)kable(top1000_df, caption ="Turkish movies in IMDB Top1000 without rating, duration and votes")
Turkish movies in IMDB Top1000 without rating, duration and votes
movie_name
movie_year
Yedinci Kogustaki Mucize
2019
Kis Uykusu
2014
Nefes: Vatan Sagolsun
2009
Ayla: The Daughter of War
2017
Babam ve Oglum
2005
Ahlat Agaci
2018
Bir Zamanlar Anadolu’da
2011
Eskiya
1996
G.O.R.A.
2004
Vizontele
2001
Her Sey Çok Güzel Olacak
1998
Note that you now have a new data frame with Turkish movies in the top 1000,containing only the title and year. Use your initial data frame and an appropriatejoin operation to fill in the duration, rating, and votes attributes of the new data frame.
Top 1000 merged dataframe
Show the code
top1000_df_merged <-merge(x=top1000_df, y=movies_df,by.x=c("movie_name", "movie_year"),by.y=c("movie_titles", "movie_years"), all.x=TRUE)kable(top1000_df_merged, caption ="Turkish movies in IMBD Top1000 with rating, duration and votes")
Turkish movies in IMBD Top1000 with rating, duration and votes
movie_name
movie_year
movie_durations
movie_ratings
movie_votes
Ahlat Agaci
2018
188
8.0
26986
Ayla: The Daughter of War
2017
125
8.3
42986
Babam ve Oglum
2005
108
8.2
91016
Bir Zamanlar Anadolu’da
2011
157
7.8
49344
Eskiya
1996
128
8.1
71695
G.O.R.A.
2004
127
8.0
66020
Her Sey Çok Güzel Olacak
1998
107
8.1
27113
Kis Uykusu
2014
196
8.0
54621
Nefes: Vatan Sagolsun
2009
128
8.0
35007
Vizontele
2001
110
8.0
38396
Yedinci Kogustaki Mucize
2019
132
8.2
54142
Order the 11 movies based on their Rank. Are these the same first high-rated 11movies in your initial data frame? If yes, does this imply that IMDb uses rankingsalone to determine their top 1000 movie list? If not, what does this imply?
Show the code
top1000_df_merged <- top1000_df_merged[order(top1000_df_merged$movie_ratings, decreasing =TRUE),]kable(top1000_df_merged, caption ="Turkish movies in IMBD Top1000, ordered by rankings.")
Turkish movies in IMBD Top1000, ordered by rankings.
movie_name
movie_year
movie_durations
movie_ratings
movie_votes
2
Ayla: The Daughter of War
2017
125
8.3
42986
3
Babam ve Oglum
2005
108
8.2
91016
11
Yedinci Kogustaki Mucize
2019
132
8.2
54142
5
Eskiya
1996
128
8.1
71695
7
Her Sey Çok Güzel Olacak
1998
107
8.1
27113
1
Ahlat Agaci
2018
188
8.0
26986
6
G.O.R.A.
2004
127
8.0
66020
8
Kis Uykusu
2014
196
8.0
54621
9
Nefes: Vatan Sagolsun
2009
128
8.0
35007
10
Vizontele
2001
110
8.0
38396
4
Bir Zamanlar Anadolu’da
2011
157
7.8
49344
Let’s take a look at the movies dataframe, ordered by rankings.
Clearly we can see that two dataframes above are not the same. We can say that IMDB not just use the rankings. First thing that I realized is there is not any movie created by before the 1996, so IMDb cares the creation date and older movies are not lucky in this ranking calculation.