movies <-data.frame(title, year, duration, rating, vote)movies <-arrange(movies, desc(rating))top_5_movies <-head(movies, 5)last_5_movies <-tail(movies, 5)kable(rbind(top_5_movies, last_5_movies), caption ="Best and Worst 5 Movies")
Best and Worst 5 Movies
title
year
duration
rating
vote
1
Hababam Sinifi
1975
87
9.2
42515
2
CM101MMXI Fundamentals
2013
139
9.1
46998
3
Tosun Pasa
1976
90
8.9
24330
4
Hababam Sinifi Sinifta Kaldi
1975
95
8.9
24370
5
Süt Kardesler
1976
80
8.8
20890
466
Cumali Ceber 2
2018
100
1.2
10230
467
Müjde
2022
NA
1.2
9920
468
15/07 Safak Vakti
2021
95
1.2
20608
469
Cumali Ceber: Allah Seni Alsin
2017
100
1.0
39269
470
Reis
2017
108
1.0
73975
I watched the first 5 movies on the list. 4 of these are Yeşilçam films that have not lost their importance for years and are known to everyone, therefore they deserve the points they received, but at the same time, films that have a place in world cinema and can compete with these films should also be among these Yeşilçam films. In my opinion, there are other films that should be at least as high as the Yeşilçam films on this list.
I can’t comment because I haven’t watched the last 5 movies.
b) My Favorite Movies
fav_movies <-c("Ise Yarar Bir Sey", "Ölümlü Dünya 2", "Kurak Günler")fav_movies_data <- movies[movies$title %in% fav_movies, ]kable(rbind(fav_movies_data), caption ="My Favorite Movies")
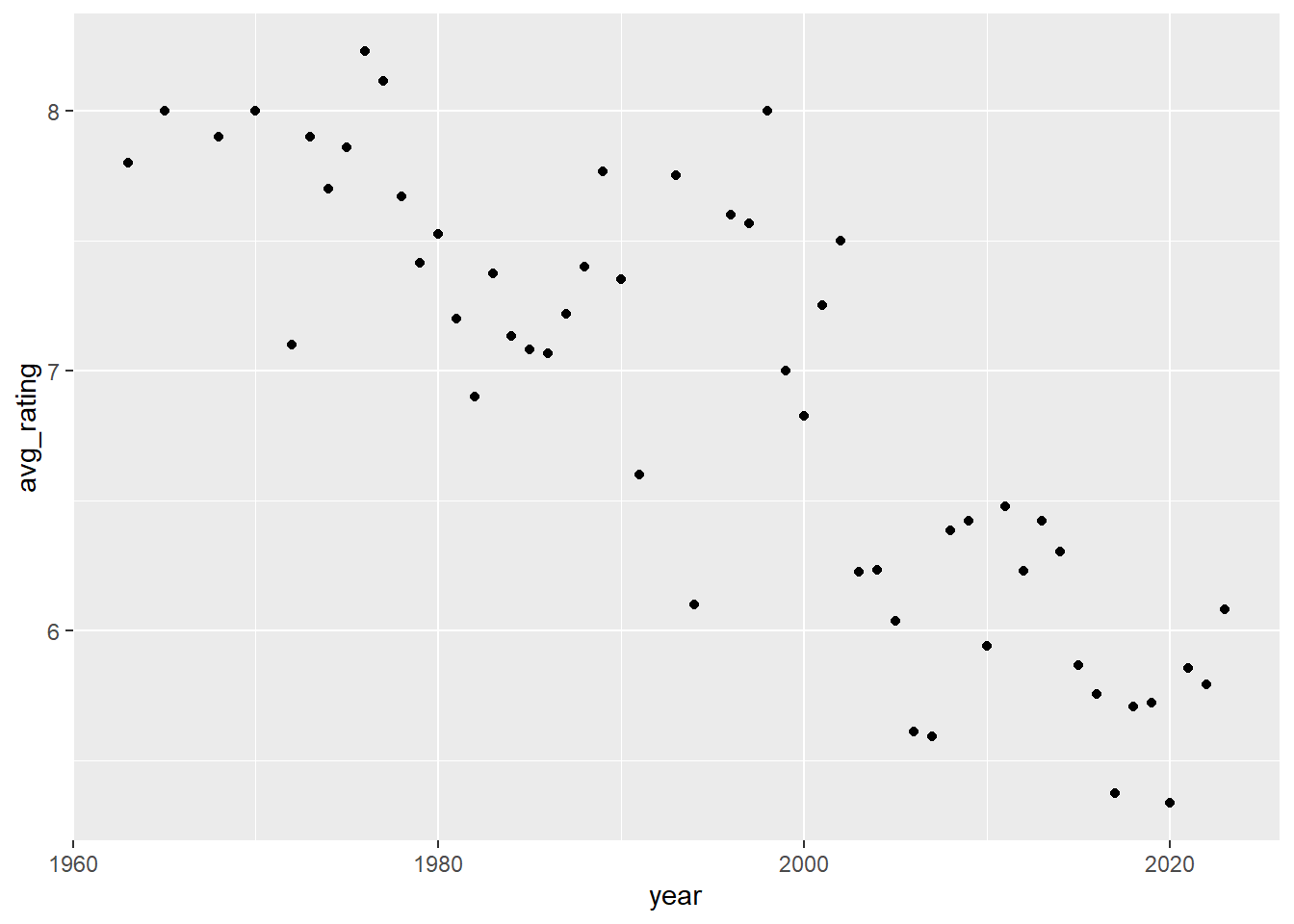
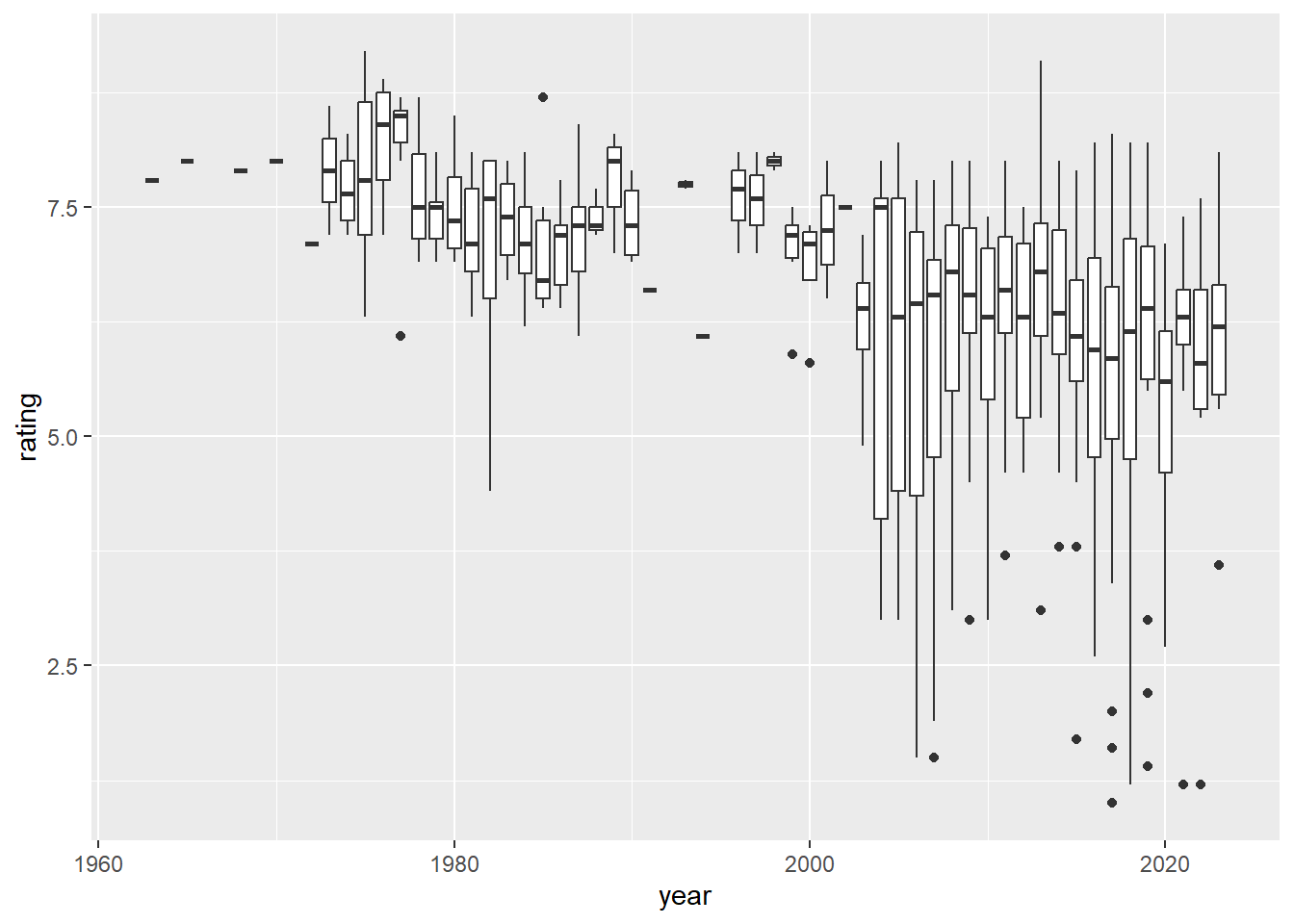
As can be seen from the plot, average ratings decrease as the years increase.
ggplot(movies, aes(x = year, y = rating, group = year)) +geom_boxplot()
d) Do you believe there is a relationship between the number of votes a movie received and its rating? Investigate the correlation between Votes and Ratings.
cor(movies$vote, movies$rating)
[1] 0.1309764
e)Do you believe there is a relationship between a movie's duration and its rating? Investigate the correlation between Duration and Ratings.
final_df <- movies %>%inner_join(top1000_df, by =c("title", "year"))kable(rbind(final_df), caption="Turkish Movies in IMDB Top 1000")
Turkish Movies in IMDB Top 1000
title
year
duration
rating
vote
Ayla: The Daughter of War
2017
125
8.3
42997
Yedinci Kogustaki Mucize
2019
132
8.2
54182
Babam ve Oglum
2005
108
8.2
91046
Eskiya
1996
128
8.1
71704
Her Sey Çok Güzel Olacak
1998
107
8.1
27124
Kis Uykusu
2014
196
8.0
54654
Ahlat Agaci
2018
188
8.0
27022
Nefes: Vatan Sagolsun
2009
128
8.0
35026
G.O.R.A.
2004
127
8.0
66037
Vizontele
2001
110
8.0
38407
Bir Zamanlar Anadolu’da
2011
157
7.8
49374
final_df <-arrange(final_df, desc(rating))kable(rbind(final_df), caption="Turkish Movies in IMDB Top 1000 by Ranked")
Turkish Movies in IMDB Top 1000 by Ranked
title
year
duration
rating
vote
Ayla: The Daughter of War
2017
125
8.3
42997
Yedinci Kogustaki Mucize
2019
132
8.2
54182
Babam ve Oglum
2005
108
8.2
91046
Eskiya
1996
128
8.1
71704
Her Sey Çok Güzel Olacak
1998
107
8.1
27124
Kis Uykusu
2014
196
8.0
54654
Ahlat Agaci
2018
188
8.0
27022
Nefes: Vatan Sagolsun
2009
128
8.0
35026
G.O.R.A.
2004
127
8.0
66037
Vizontele
2001
110
8.0
38407
Bir Zamanlar Anadolu’da
2011
157
7.8
49374
We see that this is not the same as the first dataframe. When I examined the first dataframe, only one of the first 11 movies was released after 2000. In this dataframe, only 2 dataframes were released before 2000. In other words, IMDb may consider the year parameter more than ratings in its rankings.