Assignment 2
My second assignment has 4 parts.
Part 1
Using the filters on https://m.imdb.com/search, Turkish movies with more than 2500 reviews are saved in the URLs.
Show the code
library(tidyverse)
library(rvest)
library(knitr)
library(ggplot2)
library(stringr)
first <- "https://m.imdb.com/search/title/?title_type=feature&release_date=,2009-12-31&num_votes=2500,&country_of_origin=TR&count=250"
second <- "https://m.imdb.com/search/title/?title_type=feature&release_date=2010-01-01,2023-12-31&num_votes=2500,&country_of_origin=TR&count=250"
url <- c(first,second)Part 2
Made web scrapping to create a Data Frame with columns: Title, Year, Duration, Rating, Votes.
Show the code
# Initialize an empty data frame
movies <- tibble(Title = character(), Year = numeric(), Duration = character(), Rating = numeric(), Votes = numeric())
# Function to convert duration from to minutes
convert_to_minutes <- function(time_str) {
if (str_detect(time_str, "h")) {
# "h" ve "m" arasındaki dakikaları ve "h"den önceki saatleri bul
hours <- as.numeric(str_extract(time_str, "\\d+(?=h)"))
minutes <- as.numeric(str_extract(time_str, "(?<=h)\\s*\\d+"))
total_minutes <- hours * 60 + ifelse(is.na(minutes), 0, minutes)
} else {
# "h" bulunmuyorsa ilk iki karakteri al
total_minutes <- as.numeric(substr(time_str, 1, str_detect(time_str, "m")*2))
}
return(total_minutes)
}
# Loop through each URL
for (i in url) {
data_html <- read_html(i)
# Extracting movie titles
title_names <- data_html |> html_nodes('.ipc-title__text') |> html_text()
title_names <- tail(head(title_names, -1), -1)
title_names <- str_split(title_names, " ", n = 2)
title_names <- unlist(lapply(title_names, function(x) {x[2]}))
# Extracting years
year <- data_html %>% html_nodes(".sc-43986a27-7.dBkaPT.dli-title-metadata")
year <- html_text(year)
year <- substr(year, 1, 4)
year <- as.numeric(year)
# Extracting durations
duration <- data_html %>% html_nodes(".sc-43986a27-7.dBkaPT.dli-title-metadata")
duration <- html_text(duration)
duration <- substr(duration, start = 5, stop = 14)
# Extracting ratings
rating <- data_html %>% html_nodes(".ipc-rating-star.ipc-rating-star--base.ipc-rating-star--imdb.ratingGroup--imdb-rating")
rating <- html_text(rating)
rating <- substr(rating, 1, 3)
rating <- as.numeric(rating)
# Extracting votes
vote <- data_html %>% html_nodes(".sc-53c98e73-0.kRnqtn")
vote <- html_text(vote)
vote <- sub("Votes", "" ,vote)
vote <- sub(",", "", vote)
vote <- as.numeric(vote)
temp <- tibble(Title = title_names, Year = year, Duration = duration, Rating = rating, Votes = vote)
# Append to the main data frame
movies <- bind_rows(movies, temp)
}
#The function written above is run to organize the durations of the films
duration_final <- sapply(movies$Duration, convert_to_minutes)
movies$Duration <- duration_final
# Final results
kable(head(movies,10), caption = "Turkish Movies")| Title | Year | Duration | Rating | Votes |
|---|---|---|---|---|
| Nefes: Vatan Sagolsun | 2009 | 128 | 8.0 | 35029 |
| Babam ve Oglum | 2005 | 108 | 8.2 | 91051 |
| Masumiyet | 1997 | 110 | 8.1 | 19315 |
| Kader | 2006 | 103 | 7.8 | 16282 |
| Uzak | 2002 | 110 | 7.5 | 22381 |
| Eskiya | 1996 | 128 | 8.1 | 71705 |
| A.R.O.G | 2008 | 127 | 7.3 | 44642 |
| Sevmek Zamani | 1965 | 86 | 8.0 | 7138 |
| Hababam Sinifi | 1975 | 87 | 9.2 | 42518 |
| Üç Maymun | 2008 | 109 | 7.3 | 22670 |
Part 3
Let’s conduct an EDA on the data set!!!
a. Arranged the data frame in descending order by Rating. Presented the top 5 and bottom 5 movies based on user ratings.
Show the code
top_5_movies <- movies |> arrange(desc(Rating))
kable(head(top_5_movies, 5), caption = "Top 5 Movies")| Title | Year | Duration | Rating | Votes |
|---|---|---|---|---|
| Hababam Sinifi | 1975 | 87 | 9.2 | 42518 |
| CM101MMXI Fundamentals | 2013 | 139 | 9.1 | 46999 |
| Tosun Pasa | 1976 | 90 | 8.9 | 24330 |
| Hababam Sinifi Sinifta Kaldi | 1975 | 95 | 8.9 | 24370 |
| Süt Kardesler | 1976 | 80 | 8.8 | 20890 |
As a member of Generation Z, I can’t understand why Yeşilçam films are still so loved. I think their ongoing popularity is not because they are genuinely great films, but rather due to a nostalgia for the old Turkey.
Show the code
bottom_5_movies <- movies |> arrange(Rating)
kable(head(bottom_5_movies, 5), caption = "Bottom 5 Movies")| Title | Year | Duration | Rating | Votes |
|---|---|---|---|---|
| Cumali Ceber: Allah Seni Alsin | 2017 | 100 | 1.0 | 39269 |
| Reis | 2017 | 108 | 1.0 | 73974 |
| Cumali Ceber 2 | 2018 | 100 | 1.2 | 10230 |
| Müjde | 2022 | 48 | 1.2 | 9920 |
| 15/07 Safak Vakti | 2021 | 95 | 1.2 | 20608 |
In my opinion, take these films and throw them in the trash.
b. Let’s check my favorite movies :D
Show the code
my_favs = c("Ölümlü Dünya", "Ölümlü Dünya 2", "G.O.R.A.", "Eyyvah Eyvah", "Babam ve Oglum")
kable(head(movies |> arrange(desc(Rating)) |> mutate(Rank = row_number()) |> filter(Title %in% my_favs), 5), caption = "My Favorites")| Title | Year | Duration | Rating | Votes | Rank |
|---|---|---|---|---|---|
| Babam ve Oglum | 2005 | 108 | 8.2 | 91051 | 23 |
| G.O.R.A. | 2004 | 127 | 8.0 | 66041 | 39 |
| Ölümlü Dünya | 2018 | 107 | 7.6 | 30293 | 87 |
| Ölümlü Dünya 2 | 2023 | 117 | 7.4 | 3558 | 122 |
| Eyyvah Eyvah | 2010 | 104 | 7.0 | 21445 | 211 |
c. Visualization of the dataset
Show the code
movies |> group_by(Year) |> summarise(rating_ave =
mean(Rating)) |> ggplot(aes(x = Year,
y = rating_ave)) + geom_smooth(method = "lm", se = FALSE, color = "blue", formula = y ~ x) + ylab("Average Ratings of Turkish Movies") + geom_point()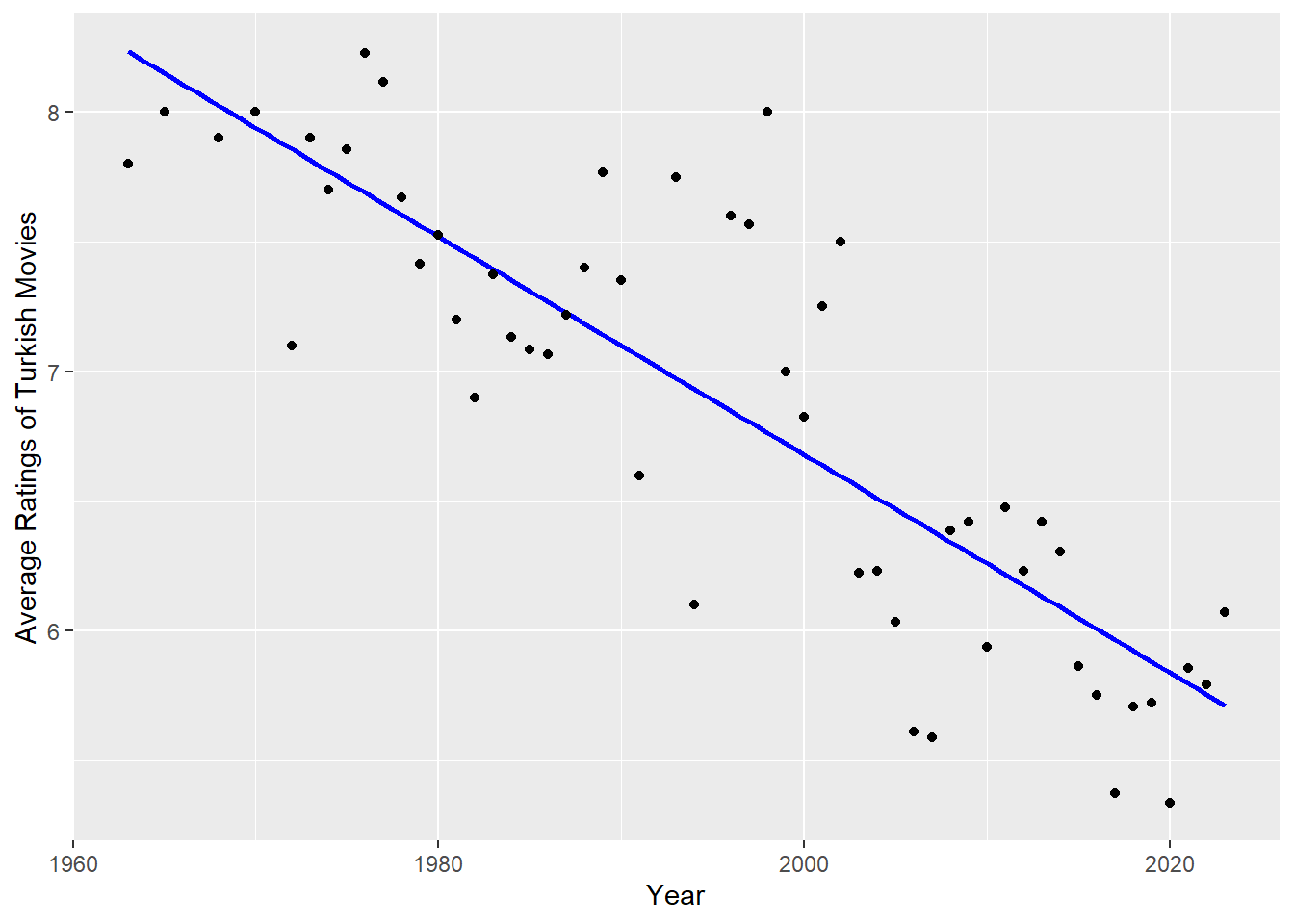
That’s sad…
Show the code
movies %>% group_by(Year) |> summarise(movies_num = n()) |> ungroup() |> ggplot(aes(x = Year, y = movies_num)) + ylab("Number of Turkish Movies") + geom_point()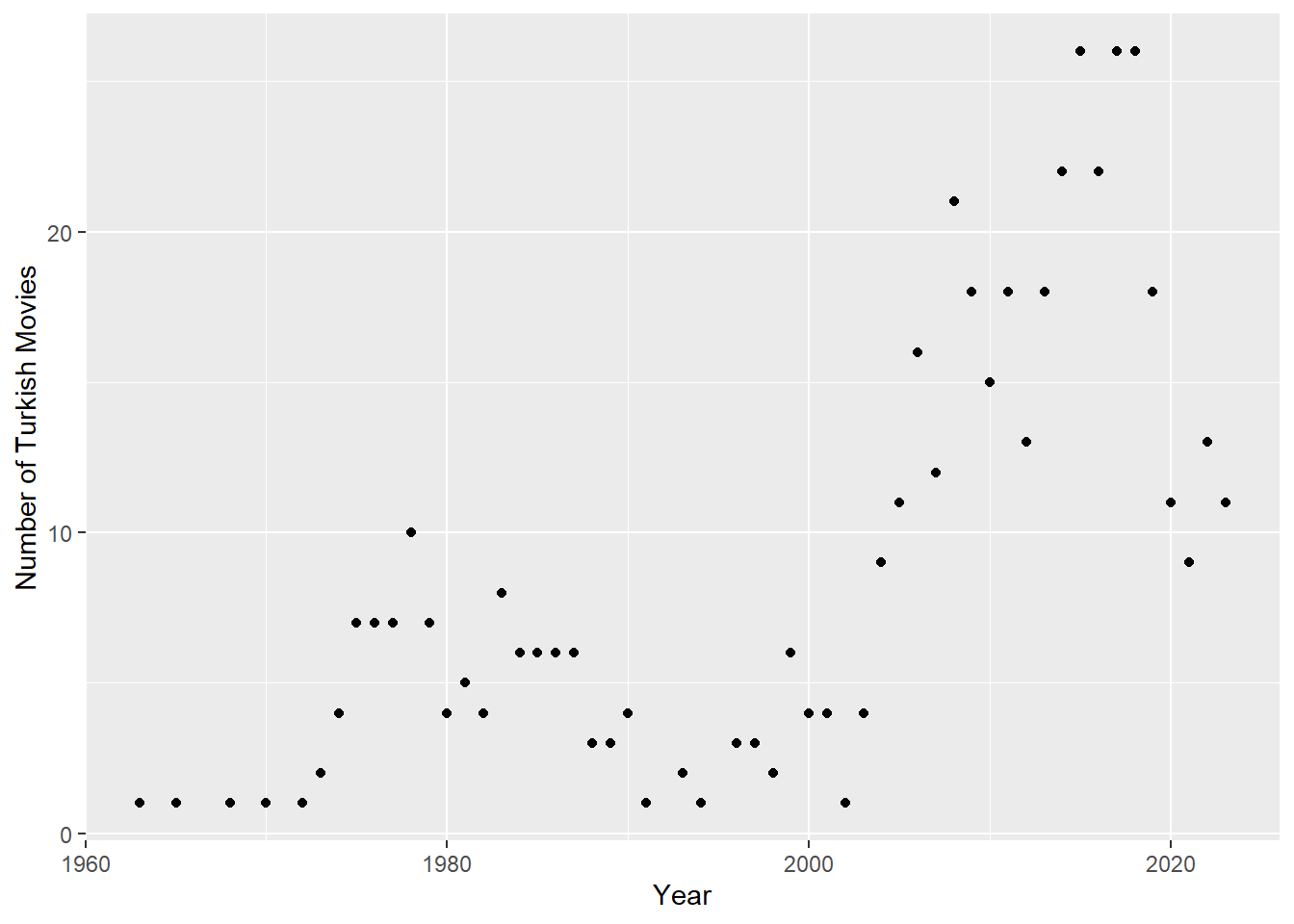
Show the code
movies |> ggplot(aes(x = Year, y = Rating, group = Year, fill = Year)) + geom_boxplot()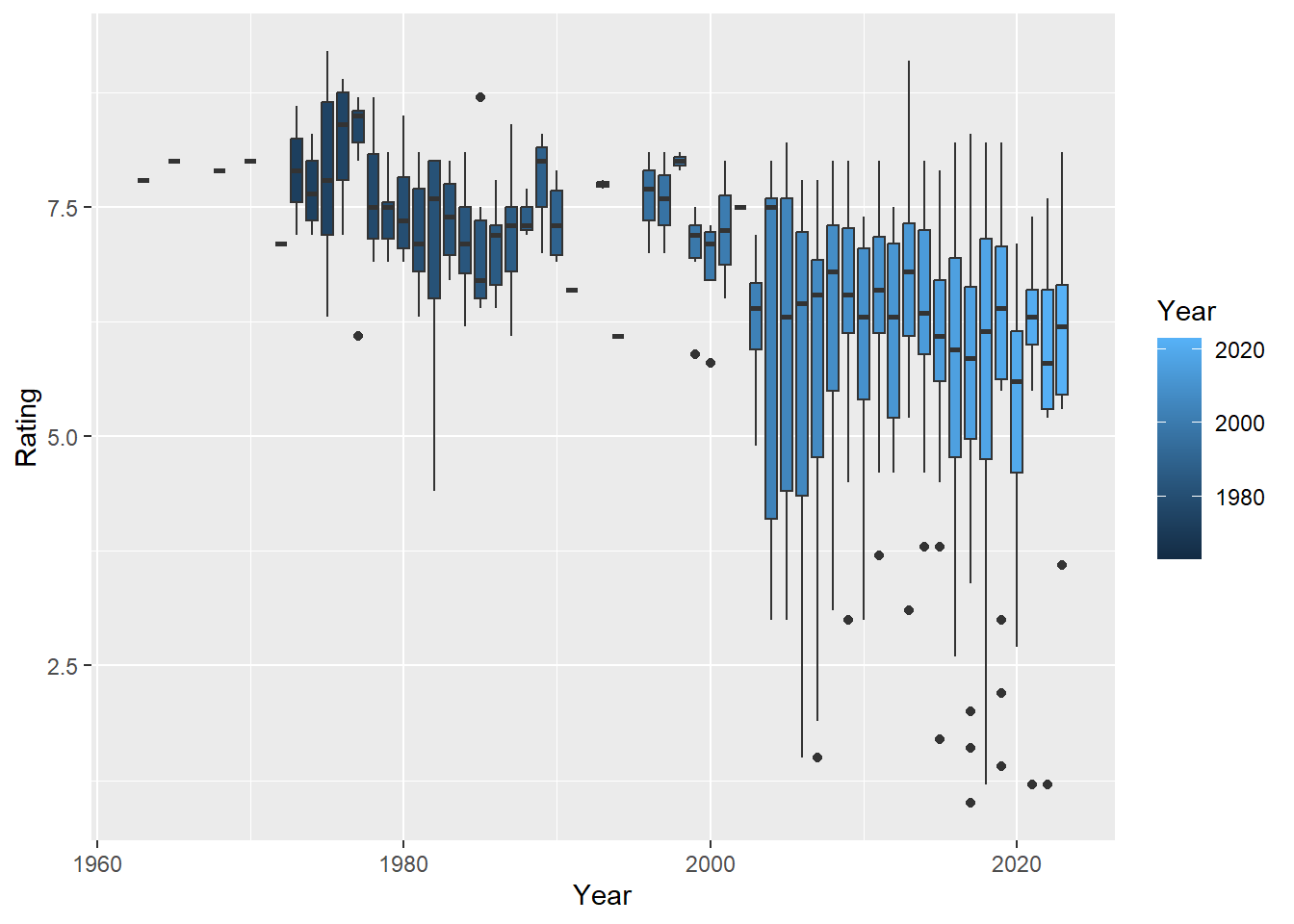
d. Correlation between the number of votes a movie received and its rating
Show the code
ggplot(movies, aes(x = log(Votes), y = Rating)) + geom_point()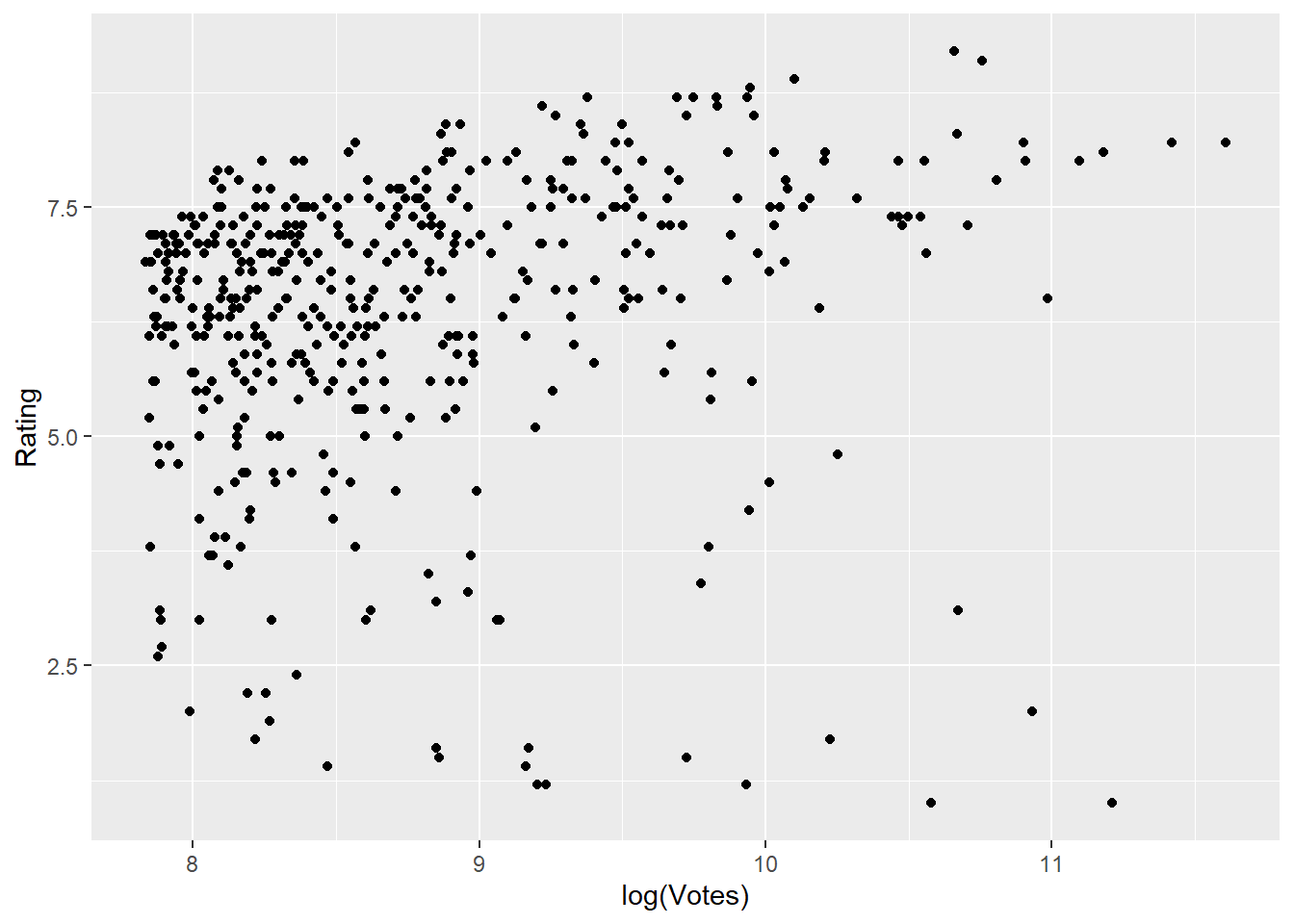
Show the code
corr1 = cor(movies$Rating, movies$Votes)
print(paste("Correlation is:", corr1))[1] “Correlation is: 0.131089313642832”
Correlation value is small. By looking at the graph, we can’t say there is a strong relationship between votes and ratings.
e. Correlation between a movie’s duration and its rating
Show the code
ggplot(movies, aes(x = Rating, y = Duration)) + geom_point()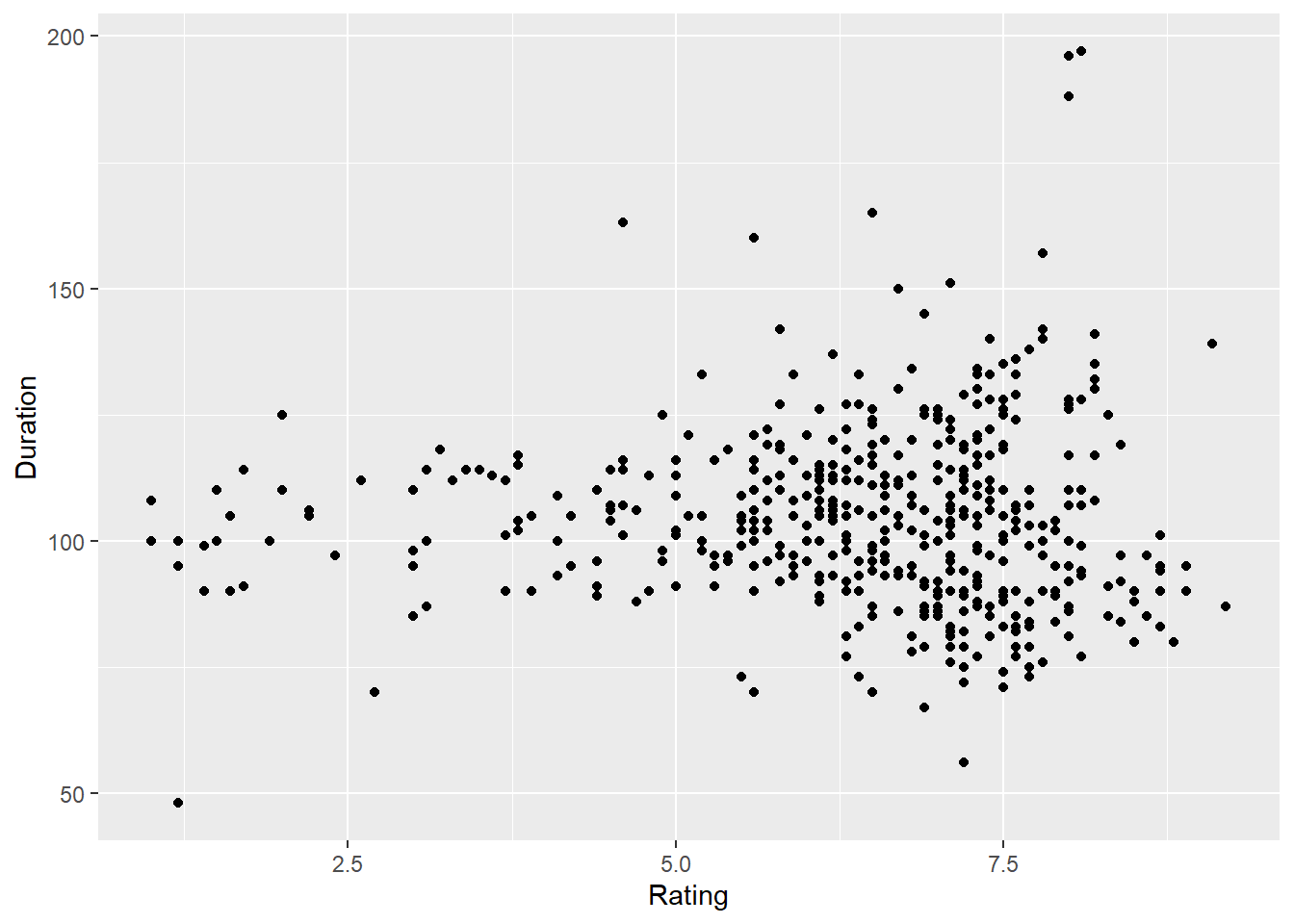
Show the code
corr2 = cor(movies$Rating, movies$Duration)
print(paste("Correlation is:", corr2))[1] “Correlation is: 0.0357059353259163”
Correlation value is too small. There is almost no linear relationship between duration and rating.
Part 4
Turkish movies that are in the top 1000 movies on IMDb:
Show the code
url <- "https://m.imdb.com/search/title/?title_type=feature&groups=top_1000&country_of_origin=TR"
new_html <- read_html(url)
title_names2 <- new_html |> html_nodes('.ipc-title__text') |> html_text()
title_names2 <- tail(head(title_names2, -1), -1)
title_names2 <- str_split(title_names2, " ", n = 2)
title_names2 <- unlist(lapply(title_names2, function(x) {x[2]}))
year2 <- new_html %>% html_nodes(".sc-43986a27-7.dBkaPT.dli-title-metadata")
year2 <- html_text(year2)
year2 <- substr(year2, 1, 4)
year2 <- as.numeric(year2)
top_1000 <- tibble(Title = title_names2, Year = year2)
kable(top_1000, caption = "Turkish Movies in IMDb Top 1000")| Title | Year |
|---|---|
| Yedinci Kogustaki Mucize | 2019 |
| Kis Uykusu | 2014 |
| Nefes: Vatan Sagolsun | 2009 |
| Ayla: The Daughter of War | 2017 |
| Babam ve Oglum | 2005 |
| Ahlat Agaci | 2018 |
| Bir Zamanlar Anadolu’da | 2011 |
| Eskiya | 1996 |
| G.O.R.A. | 2004 |
| Vizontele | 2001 |
| Her Sey Çok Güzel Olacak | 1998 |
Let’s find the duration, rating and votes of these movies by using left join on Turkish Movies Data Frame, then order by their ratings.
Show the code
top_1000_joined <- top_1000 |> left_join(movies, by = "Title", suffix = c(" ", " "))
kable((top_1000_joined |> arrange(desc(Rating))), caption = "Turkish Movies in IMDb Top1000 Ordered by Ratings")| Title | Year | Duration | Rating | Votes |
|---|---|---|---|---|
| Ayla: The Daughter of War | 2017 | 125 | 8.3 | 43001 |
| Yedinci Kogustaki Mucize | 2019 | 132 | 8.2 | 54193 |
| Babam ve Oglum | 2005 | 108 | 8.2 | 91051 |
| Eskiya | 1996 | 128 | 8.1 | 71705 |
| Her Sey Çok Güzel Olacak | 1998 | 107 | 8.1 | 27128 |
| Kis Uykusu | 2014 | 196 | 8.0 | 54660 |
| Nefes: Vatan Sagolsun | 2009 | 128 | 8.0 | 35029 |
| Ahlat Agaci | 2018 | 188 | 8.0 | 27029 |
| G.O.R.A. | 2004 | 127 | 8.0 | 66041 |
| Vizontele | 2001 | 110 | 8.0 | 38409 |
| Bir Zamanlar Anadolu’da | 2011 | 157 | 7.8 | 49379 |
Are these the same first high-rated 11 movies in our initial data frame? Let’s see!
Show the code
kable(head((movies |> arrange(desc(Rating))),11), caption = "Turkish Movies Top 11")| Title | Year | Duration | Rating | Votes |
|---|---|---|---|---|
| Hababam Sinifi | 1975 | 87 | 9.2 | 42518 |
| CM101MMXI Fundamentals | 2013 | 139 | 9.1 | 46999 |
| Tosun Pasa | 1976 | 90 | 8.9 | 24330 |
| Hababam Sinifi Sinifta Kaldi | 1975 | 95 | 8.9 | 24370 |
| Süt Kardesler | 1976 | 80 | 8.8 | 20890 |
| Saban Oglu Saban | 1977 | 90 | 8.7 | 18536 |
| Zügürt Aga | 1985 | 101 | 8.7 | 16140 |
| Neseli Günler | 1978 | 95 | 8.7 | 11810 |
| Kibar Feyzo | 1978 | 83 | 8.7 | 17126 |
| Hababam Sinifi Uyaniyor | 1976 | 94 | 8.7 | 20641 |
| Canim Kardesim | 1973 | 85 | 8.6 | 10099 |
It can be clearly seen from here that IMDb takes care to include more recent movies when creating the Top 1000 list. Because while the list of the top 11 Turkish movies consists almost entirely of films produced before 1990, the Turkish movies in the top 1000 list are productions from after 1990.