── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Show the code
library(stringr)library(rvest)
Attaching package: 'rvest'
The following object is masked from 'package:readr':
guess_encoding
Show the code
library(ggplot2)library(knitr)library(reshape2)
Attaching package: 'reshape2'
The following object is masked from 'package:tidyr':
smiths
Show the code
library(dplyr)library(magrittr)
Attaching package: 'magrittr'
The following object is masked from 'package:purrr':
set_names
The following object is masked from 'package:tidyr':
extract
Show the code
library(kableExtra)
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rows
Show the code
# Defining the url before 2010login_url_1 <-"https://m.imdb.com/search/title/?title_type=feature&release_date=,2009-12-31&num_votes=2500,&country_of_origin=TR&count=250"# Defining the url years between 2010 and nowlogin_url_2 <-"https://m.imdb.com/search/title/?title_type=feature&release_date=2010-01-01,2023-12-28&num_votes=2500,&country_of_origin=TR&count=250"
Question 2
Show the code
# Fonksiyon: IMDb verilerini çekme ve temizlemescrape_imdb_data <-function(url) { data <-read_html(url) name <- data %>%html_nodes('.ipc-title__text') %>%html_text() rating <- data %>%html_nodes('.ipc-rating-star--base') %>%html_attr('aria-label') %>%str_extract("\\d+\\.\\d+|\\d+") %>%map_dbl(~ifelse(is.na(.x), NA_real_, as.numeric(.x))) year <- data %>%html_nodes(xpath ='//*[contains(@class,"sc-43986a27-7")]') %>%html_text() %>%str_extract("\\d{4}") %>%map_dbl(~ifelse(is.na(.x), NA_real_, as.numeric(.x))) duration <- data %>%html_nodes(xpath ='//*[contains(@class,"sc-43986a27-7")]') %>%html_text() %>%str_extract("\\d+h \\d+m|\\d+h") %>%str_replace_all("h", ":") %>%str_replace_all("m", "") %>%str_replace_all("^(:\\d+)$", "0\\1") %>%# Sadece dakika varsa, saat olarak "0" ekleyinstr_split(":") %>%map_dbl(~sum(as.numeric(.x) *c(60, 1), na.rm =TRUE)) vote <- data %>%html_nodes('.kRnqtn') %>%html_text() %>%parse_number()# Uzunluğu eşitlemek için kırpma işlemi min_length <-min(length(name), length(rating), length(year), length(duration), length(vote)) name <- name[1:min_length] rating <- rating[1:min_length] year <- year[1:min_length] duration <- duration[1:min_length] vote <- vote[1:min_length]return(data.frame(name, rating, year, duration, vote))}# Verileri çekmemovies_1 <-scrape_imdb_data(login_url_1)movies_2 <-scrape_imdb_data(login_url_2)movies <-bind_rows(movies_1, movies_2)# Sonuçları kontrol etmeprint(head(movies, 10))
name rating year duration vote
1 Advanced search 8.0 2009 1205528 35023
2 1. Nefes: Vatan Sagolsun NA 2005 1203108 91038
3 2. Babam ve Oglum 8.2 1997 1198310 19298
4 3. Masumiyet NA 2006 1203703 16266
5 4. Kader 8.1 2002 1201310 22374
6 5. Uzak NA 1996 1197728 71704
7 6. Eskiya 7.8 2008 1204927 44635
8 7. A.R.O.G NA 1965 1179086 7132
9 8. Sevmek Zamani 7.5 1975 1185087 42512
10 9. Hababam Sinifi NA 2008 1204909 22664
Question 3
a-)
Show the code
# Sorting movies by ratingsorted_movies <- movies %>%arrange(desc(rating))# Top 5 moviestop_5_movies <-head(sorted_movies, 5)# Bottom 5 moviesbottom_5_movies <-tail(sorted_movies, 5)# Displaying the resultstop_5_movies
name rating year duration vote
1 16. Kurtlar Vadisi: Irak 9.2 1982 1189307 14307
2 76. Okul tirasi 9.1 2018 1210913 4995
3 48. Yumurta 8.9 2009 1205498 7087
4 176. Varyemez 8.9 1978 1186888 8939
5 144. 11'e 10 Kala 8.8 1983 1189887 4069
Show the code
bottom_5_movies
name rating year duration vote
466 239. Romantik Komedi NA 2012 1207301 3950
467 241. Açela NA 2015 1209114 27603
468 243. Resistance Is Life NA 2016 1209688 2657
469 245. 15/07 Safak Vakti NA 2018 1210896 2640
470 247. Sihirbazlik Okulunda Bir Türk NA 2018 0 2565
I’ve watched two of them, and I believe the ratings are accurate.
I haven’t watched any of them
b-)
Here are my top three favorite movies from that list.
Show the code
# List column names in your data frame# knitr paketini yükleyinlibrary(knitr)# Örnek veri çerçevesi (sorted_movies) oluşturun# Bu sadece bir örnek, gerçek veri çerçeveniz farklı olabilirsorted_movies <-data.frame(TITLE =c("Ayla: The Daughter of War", "Babam ve Oglum", "Mucize", "Diğer Film 1", "Diğer Film 2"),Year =c(2017, 2005, 2015, 2010, 2020),Rating =c(8.4, 8.5, 7.8, 6.5, 7.0))# Belirli başlıklara göre filtreleme yapınfiltered_movies <- sorted_movies[sorted_movies$TITLE %in%c("Ayla: The Daughter of War", "Babam ve Oglum", "Mucize"), ]# Filtrelenmiş veriyi kable ile tablo olarak gösterinkable(filtered_movies)
TITLE
Year
Rating
Ayla: The Daughter of War
2017
8.4
Babam ve Oglum
2005
8.5
Mucize
2015
7.8
c-)
Show the code
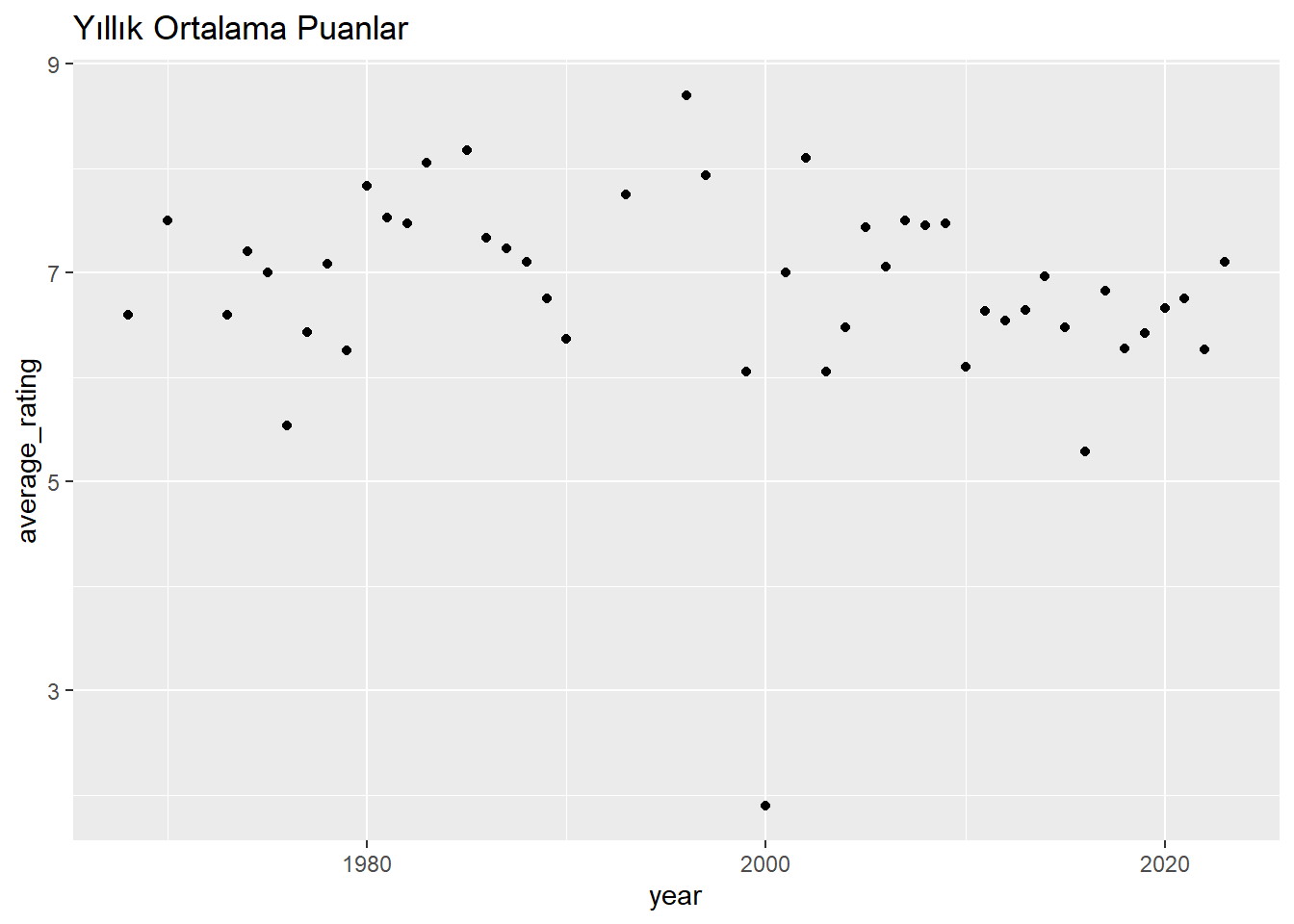
# Veri setinizdeki eksik değerleri dikkate alarak, yıllık ortalama puanları ve film sayısını hesaplayınyearly_averages <- movies %>%drop_na(rating) %>%# Eksik puanları içermeyen satırları seçingroup_by(year) %>%summarise(average_rating =mean(rating),movie_count =n())# Yıllık ortalama puanların dağılımını gösteren bir saçılma grafiği oluşturunggplot(yearly_averages, aes(x = year, y = average_rating)) +geom_point() +labs(title ="Yıllık Ortalama Puanlar")
Show the code
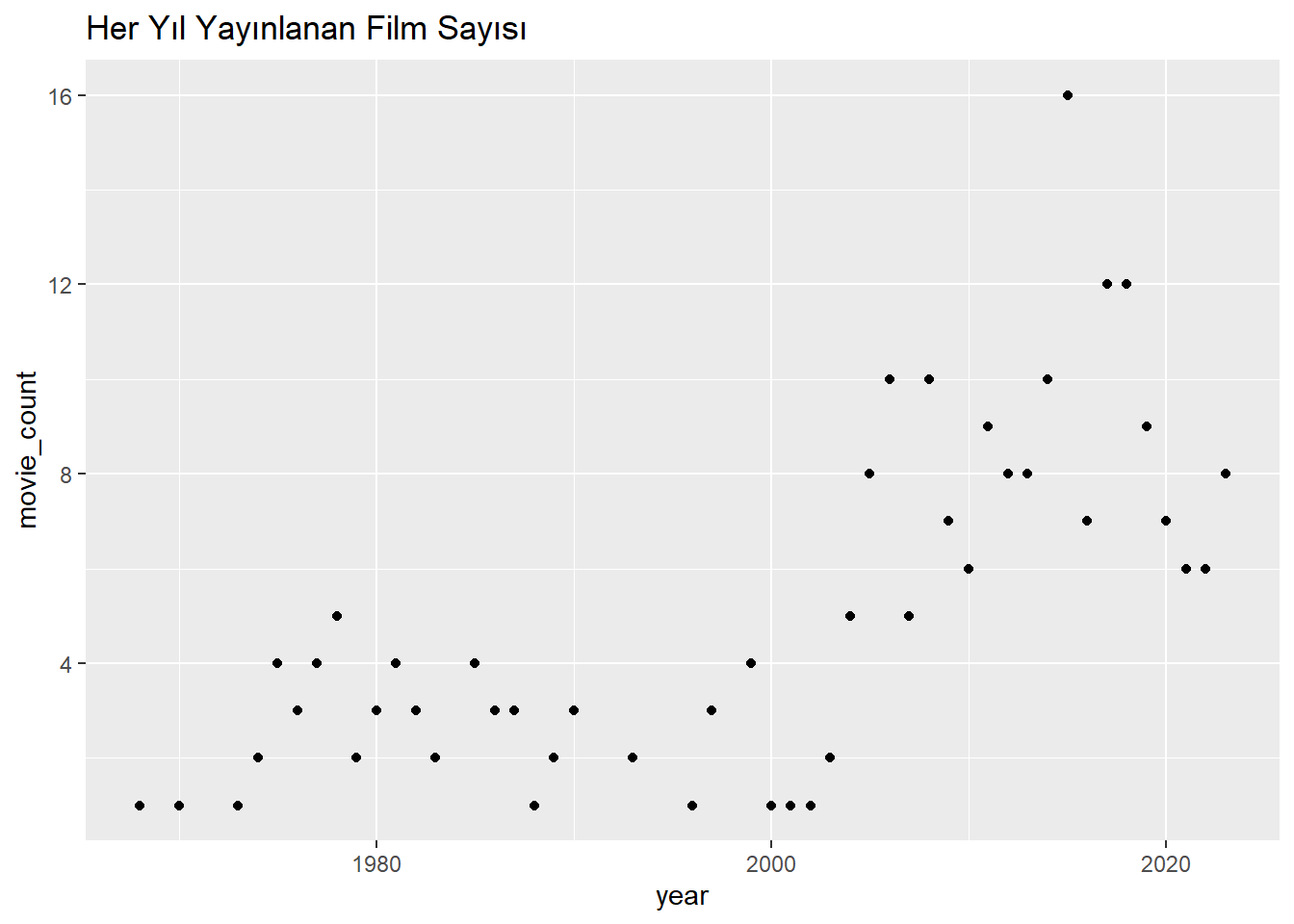
# Yıllara göre çıkan film sayısını gösteren bir saçılma grafiği oluşturunggplot(yearly_averages, aes(x = year, y = movie_count)) +geom_point() +labs(title ="Her Yıl Yayınlanan Film Sayısı")
Over time, it shows an upward trend in ratings.
d-)
Show the code
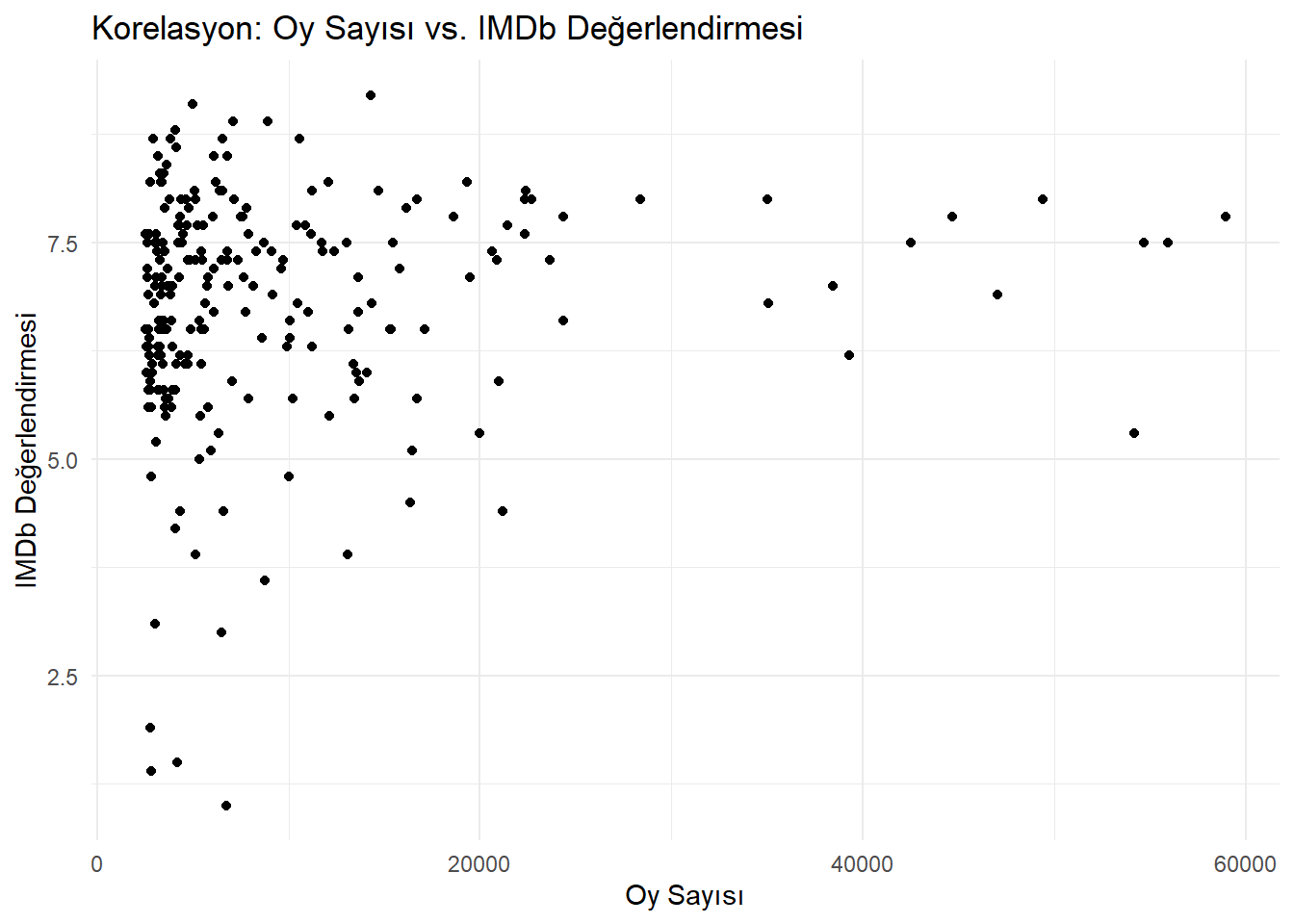
# Korelasyon hesaplama ve eksik değerleri ele almacorrelation_votes_ratings <-cor(movies$vote, movies$rating, use ="complete.obs")# Scatter plot oluşturmalibrary(ggplot2)ggplot(data =na.omit(movies), aes(x = vote, y = rating)) +geom_point() +labs(title ="Korelasyon: Oy Sayısı vs. IMDb Değerlendirmesi",x ="Oy Sayısı",y ="IMDb Değerlendirmesi" ) +theme_minimal()
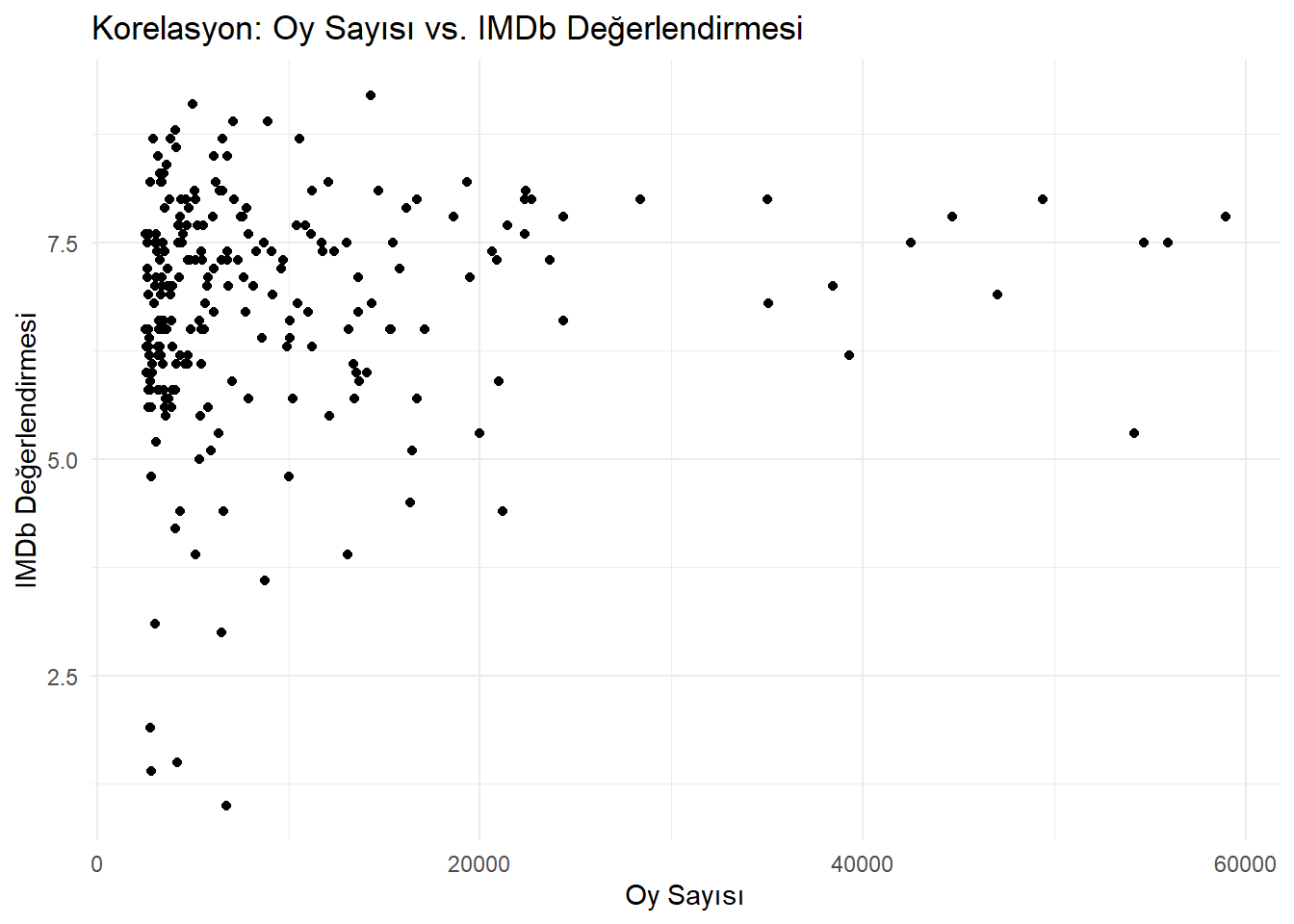
# Korelasyon hesaplama ve eksik değerleri ele almacorrelation_votes_ratings <-cor(movies$vote, movies$rating, use ="complete.obs")# Scatter plot oluşturmalibrary(ggplot2)ggplot(data =na.omit(movies), aes(x = vote, y = rating)) +geom_point() +labs(title ="Korelasyon: Oy Sayısı vs. IMDb Değerlendirmesi",x ="Oy Sayısı",y ="IMDb Değerlendirmesi" ) +theme_minimal()
The correlation coefficient, which is determined as 0.1075729, is quite low. Therefore, we can conclude that there is a weak linear relationship between Ratings and Votes.
With a correlation value of 0.008795358, it has a significantly low value. Therefore, we can conclude that there is a weak linear relationship between Durations and Votes at the 1% significance level.
title_new year_new
1 Yedinci Kogustaki Mucize 2019
2 Kis Uykusu 2014
3 Nefes: Vatan Sagolsun 2009
4 Ayla: The Daughter of War 2017
5 Babam ve Oglum 2005
6 Ahlat Agaci 2018
7 Bir Zamanlar Anadolu'da 2011
8 Eskiya 1996
9 G.O.R.A. 2004
10 Vizontele 2001
11 Her Sey Çok Güzel Olacak 1998